Dataview 中文文档
前言
这不是严格的文档汉化,里面会有我的理解、备注等。你可以当做是文档,也可以当做是教程,但同时,这些是写给我自己的,就是我的读书笔记啦。一方面作为备忘,另一方面,学习一项技能做好的方法就是整理它的文档吧。
如果有任何问题,可以在这里(https://meta.appinn.net/t/topic/59541)联系我,当然任何其他可以联系到我的渠道也都可以。
基于 v0.5.67 SHA: 15b8d527e3d5822c5ef9bfd23f528a64769d545b
- 原始文档中的很多内链并不是必须的,甚至有一点过度(此处无贬义,只是表达不添加也没什么问题)
- 原文链接有个别是错误的
- 同样的关键词,有的地方反复添加内链,有的地方则没有
我推荐:使用右侧 TOC 导航进行跳转,通过正文内链反复跳转并无助于理解,更建议顺序阅读文档避免丢失一些细节知识。
所有高亮文字均为我个人想法(批注),非官方文档内容
插件设置
- Enable inline queries(启用内联查询)
- 内联/行内都是指内容在某行文字之内,而不是单独一段(块)
- Enable Javascript queries(启用 JS 语言查询)
- Enable inline JavaScript queries (启用 JS 内联查询)
- Enable inline field highlighting in reading view(启用阅读视图中的内联字段高亮)
- Enable inline field highlighting in Live Preview(启用实时预览中的内联字段高亮)
代码块(Codeblocks)
- DataviewjS keyword(DataviewJS 关键字)
- Inline query prefix(内联查询前缀)
- JavaScript inline query prefix(JavaScript 内联查询前缀)
- Code block inline queries(代码块内联查询)
视图(View)
- Display result count(显示结果数量)
- Warn on empty result(结果为空时显示提示信息)
- Render null as(如何渲染 null 值)
- Automatic view refreshing(当保险库有更新时自动刷新视图)(我一般关掉,不然写一个字刷新一次,太烦)
- Refresh interval(刷新频率,即笔记更新后多久刷新视图)(不想关掉,又不想过于干扰写作,可以适当调大这个值)
- Date format(日期格式)
- Date + time format(日期时间格式)
表格(Tables)
- Primary column name(主列名,表格中自动生成的链接到源文件的列名称)
- Grouped column name(组列名,当表格进行分组时,这一列的名称)
任务(Tasks)
- Automatic task completion tracking(自动任务完成追踪,开启后任务完成时会标记任务完成时间)
- Use emoji shorthand for completion(使用 emoji 简写来表示完成)
- Completion field name(完成字段名称,只有开启自动追踪,并且关闭 emoji 标记才可设置)
- Completion date format(任务完成时间格式)
- Recursive sub-task completion(递归子任务完成,即标记任务完成时这个任务的下级任务都被标记未完成)
总览(Overview)
Dataview 是一款针对你个人知识库的实时索引和查询引擎。你可以给你的笔记添加元数据(【元数据 > 添加元数据】),并使用 Dataview 查询语言(【查询语言参考】)来列出、过滤、排序或分组你的数据。Dataview 保持你的查询始终是最新的(这个选项可以自行开关),并且使数据聚合变得轻松。
你可以:
- 通过在每日笔记中记录来跟踪你的睡眠,并自动创建你的睡眠时间表的周表。
- 自动收集笔记中的书签链接,并按评分排序渲染它们。
- 自动收集与今天日期相关的页面,并在你的每日笔记中显示它们。
- 查找没有标签的页面以进行后续跟进,或展示特定标签页面的漂亮视图。
- 创建动态视图,显示记录在笔记中的即将到来的生日或事件。
以及更多事情。
Dataview 非常通用且性能高,能够轻松扩展至处理数十万条带注释的笔记而没有问题。
如果内置的查询语言(【查询语言参考】)无法满足您的需求,您可以在 Dataview API(【JavaScript 查询参考】) 上运行任意 JavaScript 代码,并在您的笔记中自行构建所需的任何实用工具。
Dataview 旨在展示和计算数据。它不是用来编辑您的笔记/元数据的,并且总是会让它们(笔记)保持原样(...除非您是通过 Dataview 切换任务(【查询语言参考 > 查询类型 > 任务】)状态。)
如何使用 Dataview
Dataview 由两大构建模块组成:数据索引(Data Indexing)和数据查询(Data Querying)。
接下来的部分应该为您提供关于使用 Dataview 能做什么以及如何操作的一般概述。请确保访问链接的页面,以了解更多关于各个部分的详细信息。
数据索引
Dataview 在您的 Markdown 文件中的元数据上运行。它不能读取您的保险库中的所有内容,而只能读取特定数据。您的一些内容,如标签和项目符号(包括任务),会自动在 Dataview 中可用(【元数据 > 添加元数据 > 隐式字段】)。您可以通过字段添加其他数据,这些字段可以位于文件顶部的 YAML Frontmatter 中(【元数据 > 添加元数据 > 如何添加字段? > Frontmatter】),或者通过使用 [key:: value] 语法在您的内容中间使用内联字段(【元数据 > 添加元数据 > 如何添加字段? > 内联字段】)。Dataview 索引这些数据,使其可供您查询。(简言之,不能全文搜索,只能根据笔记的特殊属性进行查询,或者对列表进行查询)
[!note] Dataview 索引某些信息(【元数据 > 添加元数据 > 隐式字段】),如标签和列表项,以及您通过字段添加的数据。只有在 Dataview 查询中才可用索引数据!
例如,一个文件可能看起来像这样:
---
author: "Edgar Allan Poe"
published: 1845
tags: poems
---
# The Raven
Once upon a midnight dreary, while I pondered, weak and weary,
Over many a quaint and curious volume of forgotten lore—或者像这样
#poems
# The Raven
From [author:: Edgar Allan Poe], written in (published:: 1845)
Once upon a midnight dreary, while I pondered, weak and weary,
Over many a quaint and curious volume of forgotten lore—在索引的元数据(或者您可以查询的内容)方面,它们是相同的,只是它们的注释风格不同。您想要如何注释您的元数据(【元数据 > 添加元数据)取决于您和您的个人偏好。有了这个文件,您将拥有元数据字段 "author" 可用,以及 Dataview 自动为您提供的所有隐式字段(【元数据 > 添加元数据 > 隐式字段】),比如标签或笔记标题。
在上述例子中,您无法在 Dataview 中使用诗歌本身:它是一个段落,不是元数据字段,也不是 Dataview 自动索引的内容。它不是 Dataview 索引的一部分,因此您将无法查询它。
这样做的好处是查询速度快,并且足以满足大部分需求。但是对于深度用户,这样带来的局限性也是非常大的。不过深度用户可以通过其他方法开启更复杂的查询。
数据查询
您可以借助查询来访问索引数据。
您可以用三种不同的方式来编写查询:使用 Dataview 查询语言(【查询语言、JS 和行内查询 > Dataview 查询语言 (DQL)】)、作为内联语句(【查询语言、JS 和行内查询 > 内联 DQL】),或者以最灵活但最复杂的方式:用 JavaScript 查询(【查询语言、JS 和行内查询 > Dataview JS】)。(学它的查询语言只能用在它这里,但是学习 JS 可以应用的地方可太多了,而且灵活性上 JS 也强了太多,所以我选择……)
Dataview 查询语言(DQL)为您提供了一个广泛而强大的工具箱,用于查询、显示和操作您的数据。内联查询(【查询语言、JS 和行内查询 > 内联 DQL】)使您能够在笔记中的任何地方显示一个确切的索引值。您也可以通过这种方式进行计算。有了 DQL,您可能在数据之旅中不需要任何 JavaScript。(完全按着它的思路去使用,大概确实是的。但如果自己的想法多一点,想要的多一点,还是得 JS)
DQL 查询由几个部分组成:
- 选择一种查询类型(【查询语言参考 > 查询类型】),它决定了您的查询输出外观(格式)
- 零个或一个 FROM 语句(【查询语言参考 > 数据命令 > FROM】),用于选择特定的标签或文件夹(或另一个来源)来查看
- 零到多个其他数据命令(【查询语言参考 > 数据命令】),帮助您过滤、分组和排序您想要的输出
例如,一个查询可能看起来像这样:
```dataview
LIST
```这将列出你保险库中的所有文件。(查询类型:LIST,其它参数全省略,则默认整个仓库)
对于一个有效的 DQL 查询,您需要的只有查询类型(在日历视图上,还需要一个日期字段)。
一个添加了更多限制条件的查询看起来像这个样子:
```dataview
LIST
FROM #poems
WHERE author = "Edgar Allan Poe"
```这个查询列出了您的保险库中所有带有标签 #poems 并且有一个名为 author 的字段,其值为 Edgar Allan Poe 的文件。这个查询将找到我们上面提到的例子页面。
LIST 只是您可以使用的四种查询类型之一(【查询语言参考 > 查询类型】)。例如,使用 TABLE 类型,我们可以在我们的输出中添加一些更多的信息:
```dataview
TABLE author, published, file.inlinks AS "Mentions"
FROM #poems
```返回的结果像这样:
| File (3) | author | published | Mentions |
|---|---|---|---|
| The Bells | Edgar Allan Poe | 1849 | |
| The New Colossus | Emma Lazarus | 1883 | - [[Favorite Poems]] |
| The Raven | Edgar Allan Poe | 1845 | - [[Favorite Poems]] |
尽管如此,Dataview 的能力并不仅限于此。您还可以利用函数(【查询语言参考 > 函数】)对您的数据进行操作。请注意,这些操作仅在查询内部进行 - 您文件中的数据保持不变。
```dataview
TABLE author, date(now).year - published AS "Age in Yrs", length(file.inlinks) AS "Counts of Mentions"
FROM #poems
```返回结果:
| File (3) | author | Age in Yrs | Count of Mentions |
|---|---|---|---|
| The Bells | Edgar Allan Poe | 173 | 0 |
| The New Colossus | Emma Lazarus | 139 | 1 |
| The Raven | Edgar Allan Poe | 177 | 1 |
正如您所看到的,Dataview 不仅允许您快速且始终更新地聚合您的数据,它还可以帮助您进行操作,为您提供对数据集的新见解。浏览文档以了解更多关于如何与您的数据交互的信息。
以新的方式探索您的保险库,享受乐趣!
资源和帮助
此文档不是唯一可以在您的数据之旅中帮助您的地方。查看资源和支持(【问答和资源 > 资源与支持】),获取有用页面和视频的列表。
元数据(Metadata)
这里所说的元数据、字段,具有非常相似的含义,总之就是定义一些属性,并为属性赋值。你要关注的是属性的名称(键、key),属性的值(value),这个属性是谁的。
添加元数据(Adding Metadata)
Dataview 无法查询您保管库的所有内容。为了能够搜索、过滤和显示内容,需要对该内容建立索引。某些内容会自动索引,例如项目符号点或任务列表 - 所谓的隐式字段,下面将详细介绍 - 而其他数据需要保存在元数据字段中才能通过 Dataview 访问。(总而言之,一般的笔记内容它查询不到)
什么是“字段”?
元数据字段是一对键和值。字段的值有一个数据类型(更多信息请参见此处(【元数据 > 数据类型】)),该数据类型确定该字段在查询时的行为方式。
您可以向注释、列表项或任务添加任意数量的字段。
如何添加字段?
您可以通过三种不同的方式向注释添加字段。字段的外观取决于您添加它的方式。
在任务或列表项上,您将拥有可用的 YAML Frontmatter 信息,但无法将它们添加到特定列表项。如果您只想将元数据添加到一个列表项或任务,请使用内联字段(【元数据 > 添加元数据 > 如何添加字段? > 内联字段】)。
Frontmatter
Frontmatter 是一个常见的 Markdown 扩展,它允许将 YAML 元数据添加到页面顶部。它由 Obsidian 原生支持,并在其官方文档中进行了解释。所有 YAML Frontmatter 字段将自动用作 Dataview 字段。
---
alias: "document"
last-reviewed: 2021-08-17
thoughts:
rating: 8
reviewable: false
---这样,您的笔记就有名为 alias 、 last-reviewed 和 thoughts 的元数据字段。其中每一个都有不同的数据类型:
alias是一个文本字段(【元数据 > 数据类型 > 可用字段类型 > 文本】),因为它包裹在引号中last-reviewed是一个日期(【元数据 > 数据类型 > 可用字段类型 > 日期】),因为它遵循 ISO 日期格式thoughts是一个对象字段(【元数据 > 数据类型 > 可用字段类型 > 对象】),因为它使用 YAML Frontmatter 对象语法
您可以使用下面的查询来查询该注释:
```dataview
LIST
WHERE thoughts.rating = 8
```内联字段
对于那些想要更自然外观的注释,Dataview 支持通过 Key::Value 语法的“内联”字段,您可以在文件的任何地方使用它。这允许您在需要的地方直接编写可查询的数据——例如,在句子中间。
如果您的内联字段拥有自己的一行,并且之前没有任何内容,您可以这样写:
# Markdown Page
Basic Field:: Some random Value
**Bold Field**:: Nice!所有在"::"之后的内容都是字段的值,直到下一行的行末。
::请注意,使用内联字段时,您需要在键和值之间使用双冒号 ::,这与 YAML Frontmatter 字段不同,YAML Frontmatter 只需要一个冒号就足够了。
如果您想将元数据嵌入句子内或同一行上的多个字段,您可以使用方括号语法并将字段括在方括号中:
I would rate this a [rating:: 9]! It was [mood:: acceptable].当您想要注释列表项时,例如一个任务,有元数据,总是需要使用括号语法(因为字段不是这一行唯一的信息)
- [ ] Send an mail to David about the deadline [due:: 2022-04-05].带括号的内联字段是显式将字段添加到特定列表项的唯一方法,YAML frontmatter 始终适用于整个页面(但也可在列表项的上下文中使用。)
还有另一种括号语法,它在阅读器模式下会隐藏键(即隐藏双冒号前面的部分):
This will not show the (longKeyIDontNeedWhenReading:: key).将呈现为:
This will not show the key.您可以在一个文件中将 YAML Frontmatter 和内联字段与所有语法变体一起使用。您无需只选择其中一种,而是可以混合使用它们以适合您的工作流程。
总体上,我并不喜欢这种自定义字段,因为它污染了 Markdown 语法。但又不得不说,这里的字段设计其实蛮巧妙的,很简洁,易读,即使在纯文本下,也可以轻松理解。所以我也没那么排斥,应该算是保持一种中立的态度。
字段名称
想象一下,您使用了上面在一篇注释中看到的内联字段的所有示例,那么您将可以使用以下元数据:
| 元数据键 | 净化后的元数据密钥 | 值 | 值的数据类型 |
|---|---|---|---|
Basic Field |
basic-field |
Some random Value | Text |
Bold Field |
bold-field |
Nice! | Text |
rating |
- | 9 | Number |
mood |
- | acceptable | Text |
due |
- | Date Object for 2022-04-05 | Date |
longKeyIDontNeedWhenReading |
longkeyidontneedwhenreading |
key | Text |
正如您在表中看到的,如果您在元数据键名称中使用空格或大写字母,Dataview 将为您提供该键的经过净化的版本。
带空格的键不能按原样在查询中使用。这里有两种可能性:要么使用经过清理的名称,该名称始终为小写,并用破折号代替空格,要么使用行变量语法。在常见问题解答(【问答和资源 > 常见问题解答】)中了解更多信息。
如果您愿意的话,使用大写字母的键可以原样使用。经过清理的版本允许您查询键,而不受其大小写的影响,这使得使用更加方便:您可以使用清理后的键名进行查询,例如,在两个文件中分别命名为 someMetadata 和 someMetaData,而使用清理后的键 somemetadata。(总之都会被转换为小写,即大小写无关)
表情符号和非拉丁字符的使用
命名元数据字段时不限于拉丁字符。您可以使用 UTF-8 中可用的所有字符:(可以使用中文,emoji 等)
Noël:: Un jeu de console
クリスマス:: 家庭用ゲーム機
[🎅:: a console game]
[xmas🎄:: a console game]使用 emoji 作为元数据键是可以的,但它有一些限制。在字段名称中使用 emoji 时,需要将它们放入方括号中,以便 dataview 正确识别它们。另外,请注意,在切换操作系统(即从 Windows 到 Android)时,相同的表情符号可能使用不同的字符代码,并且您在查询时可能找不到元数据。(Emoji 其实挺混乱的,虽然好看,但是用起来问题比较多,尤其是不够了解的情况下,出了问题可能都难以理解究竟出了什么问题)
任务中的简写语法是一个例外。您可以使用不带括号的简写(【元数据 > 任务和列表的元数据 > 字段简写】)。请注意,这仅适用于列出的简写 - 所有其他字段(无论是否带有表情符号)都需要使用 [key:: value] 语法。
隐式字段
即使您没有在笔记中显式添加任何元数据,dataview 也会为您提供大量开箱即用的索引数据。隐式字段的一些示例:
- 文件创建日期 (
file.cday)(当你复制、同步文件时,可能导致这个日期发生变化,从而不能准确的反应笔记真实的创建日期,所以推荐在 frontmatter 中加入文件的创建和更新日期) - 文件中的链接 (
file.outlinks) - 文件中的标签 (
file.etags) - 文件中的所有列表项(
file.lists和file.tasks)
还有很多。可用的隐式字段会有所不同,具体取决于您查看的是页面还是列表项。在页面元数据(【元数据 > 页面元数据】)和任务和列表元数据(【元数据 > 任务和列表的元数据】)上查找可用隐式字段的完整列表。
数据类型(Data Types)
Dataview 中的所有字段都有一个类型,这决定了 Dataview 如何渲染、排序和操作该字段。您可以在“添加元数据”(【元数据 > 添加元数据】)部分了解更多关于如何创建字段的信息,以及在页面(【元数据 > 页面元数据】)和任务列表(【元数据 > 任务和列表的元数据】)的元数据上有哪些可用信息。
为什么类型很重要?
Dataview 提供了您可以使用的函数(【查询语言参考 > 函数】)来修改您的元数据,并允许您编写各种复杂的查询。特定的函数需要特定的数据类型才能正确工作。这意味着您的字段的数据类型决定了您可以在这些字段上使用哪些函数以及这些函数的行为。此外,根据类型,Dataview 渲染的输出数据可能会有所不同。
大多数情况下,您不需要太担心字段的类型,但如果您想对数据执行计算和其他魔法操作,您应该了解它们。
在任何编程中,数据类型都是非常重要的,即便是在类型无需声明并可以自动转换的脚本语言中,也应该时刻了解当前数据所处的类型。
假设你有这样一个文件:
date1:: 2021-02-26T15:15
date2:: 2021-04-17 18:00
```dataview
TABLE date1, date2
WHERE file = this.file
```您将看到以下输出(取决于您为 Dataview 设置的日期和时间格式):
| File (1) | date1 | date2 |
|---|---|---|
| Untitled 2 | 3:15 PM - February 26, 2021 | 2021-04-17 18:00 |
date1 被识别为日期,而 date2 是普通的文本,对 Dataview 来说,这就是为什么 date1 被解析得与您给出的值不同的原因。在下方可以找到更多关于日期的信息(【元数据 > 数据类型 > 可用字段类型 > 日期】)。
不理解数据类型,就很难进行高级操作;而理解了数据类型,其实也就入门了编程。
可用字段类型
Dataview 预设几种字段类型,以覆盖常见的使用情况。
文本(Text)
默认的通用类型。如果一个字段不匹配更具体的类型,它就是纯文本。
Example:: This is some normal text.作为值的多行文本只能通过 YAML Frontmatter 和管道符(|)来实现:
---
poem: |
Because I could not stop for Death,
He kindly stopped for me;
The carriage held but just ourselves
And Immortality.
author: "[[Emily Dickinson]]"
title: "Because I could not stop for Death"
---对于内联字段,换行符意味着值的结束。
多行文本确实是个大麻烦,但又常常需要用到。管道符是标准的 YAML 语法,所以可以放心使用,其实还有一些其他方法,有兴趣可以了解一下。
数字(Number)
数字如 '6' 和 '3.6'。
Example:: 6
Example:: 2.4
Example:: -80在 YAML Frontmatter 中,您写数字时不需要用引号包围(引号包裹是用来说明这个内容是字符串(文本)的):
---
rating: 8
description: "A nice little horror movie"
---布尔值(Boolean)
布尔值只认识两个值:真(true)或假(false),正如编程概念中的那样。(==也可以用 0 和非零 的值,当然如果不太懂,就严格使用 true 和 false==)
Example:: true
Example:: false日期(Date)
符合 ISO8601 标准的文本将自动转换为日期对象。ISO8601 遵循格式 YYYY-MM[-DDTHH:mm:ss.nnn+ZZ]。月份之后的所有内容都是可选的。
Example:: 2021-04
Example:: 2021-04-18
Example:: 2021-04-18T04:19:35.000
Example:: 2021-04-18T04:19:35.000+06:30当查询这些日期时,您可以访问属性以获取日期的特定部分:
field.yearfield.monthfield.weekyearfield.weekfield.weekdayfield.dayfield.hourfield.minutefield.secondfield.millisecond
例如,如果您想知道日期所在的月份,可以通过 datefield.month 来访问:
birthday:: 2001-06-11
```dataview
LIST birthday
WHERE birthday.month = date(now).month
```返回这个月所有生日。对 date(now) 感到好奇吗?在“字面量”(【查询语言参考 > 字面量 > 日期】)下阅读更多。
Dataview 以人类可读的格式渲染日期对象,即 3:15 PM - February 26, 2021。您可以在 Dataview 的“设置”_“常规”中通过“日期格式”和“日期+时间格式”来调整这种格式的外观。如果您只想在特定查询中调整格式,请使用 dateformat 函数(【dateformat(date|datetime, string)" class="internal-link" target="">查询语言参考 > 函数 > 工具函数 > dateformat(date|datetime, string)】)。
持续时间(Duration)
持续时间是形如 <时间> <单位> 的文本,例如 "6 hours" 或 "4 minutes"。常见的英文缩写如 "6hrs" 或 "2m" 也是可以接受的。您可以在同一个字段中指定多个单位,即 "6hr 4min",也可以选择使用逗号分隔:"6 hours, 4 minutes"。(这种就必须使用英文了,因为程序只认识英文写法)
Example:: 7 hours
Example:: 16days
Example:: 4min
Example:: 6hr7min
Example:: 9 years, 8 months, 4 days, 16 hours, 2 minutes
Example:: 9 yrs 8 min要找到被识别为持续时间的完整值列表,您可以查阅 Dataview 文档中的 "字面量"(【查询语言参考 > 字面量 > 持续时间】) 部分,那里会列出所有被接受的时间单位和格式。
日期和持续时间类型是兼容的。这意味着您可以,例如,将持续时间加到日期上以产生一个新的日期:
departure:: 2022-10-07T15:15
length of travel:: 1 day, 3 hours
**Arrival**: `= this.departure + this.length-of-travel`当您用日期进行计算时,您也可以得到持续时间:
release-date:: 2023-02-14T12:00
`= this.release-date - date(now)` until release!!对 date(now) 感到好奇吗?在“字面量”(【查询语言参考 > 字面量 > 日期】)下阅读更多。
链接(Link)
Obsidian 链接如 [[Page]] 或者 [[Page|Page Display]]。(这里示例的是定义一个链接,其实本质上是“文本”,然后 Dataview 对文本进行解析,识别(渲染)为链接)
Example:: [[A Page]]
Example:: [[Some Other Page|Render Text]]如果您在 frontmatter 中引用链接,您需要用引号括起来,如下所示:key: "[[Link]]"。这是默认的 Obsidian 支持行为。未加引号的链接会导致无效的 YAML > frontmatter,无法再被解析。
---
parent: "[[parentPage]]"
---请注意,这只是 Dataview 的链接,而不是 Obsidian 的 - 这意味着它不会出现在外出链接中,不会在关系视图中显示,也不会在例如重命名时更新。
列表(List)
列表是多值字段。在 YAML 中,这些被定义为普通的 YAML 列表:
---
key3: [one, two, three]
key4:
- four
- five
- six
---在内联字段中,它们是以逗号分隔的列表值:
Example1:: 1, 2, 3
Example2:: "yes", "or", "no"请注意,在内联字段中,您需要将文本值用引号括起来,以便被识别为列表(参见示例 2)。"yes"、"or"、"no" 被识别为普通文本。
如果您在同一笔记中使用了两次或更多次的元数据键,dataview 将收集所有值并给出一个列表。例如:
grocery:: flour
[...]
grocery:: soap
```dataview
LIST grocery
WHERE file = this.file
```将返回一个包含 flour 和 soap 的列表。
在本文档的某些地方,您会看到“数组”这个名词。数组是 Javascript 中列表的表达方式——列表和数组是相同的。需要数组作为参数的函数也可以使用列表作为参数。
对象(Object)
对象是一个在一个父字段下的多个字段的映射。这些只能在 YAML 前置数据中定义,使用 YAML 对象语法:
---
obj:
key1: "Val"
key2: 3
key3:
- "List1"
- "List2"
- "List3"
---在查询中,您可以通过 obj.key1 等方式访问这些子值:
```dataview
TABLE obj.key1, obj.key2, obj.key3
WHERE file = this.file
```页面(笔记)元数据(Metadata on Pages)
您可以通过三种不同的方式向 Markdown 页面(笔记)添加字段——通过前置数据、内联字段和隐式字段。有关前两种可能性,请阅读“如何添加元数据”(【元数据 > 添加元数据】)。
隐式字段(页面)
Dataview 会自动向每个页面添加大量元数据。这些隐式和自动添加的字段会集中在字段 file 下。以下是可用的字段:
| 字段名称e | 数据类型e | 详细描述 |
|---|---|---|
file.name |
Text | 在 Obsidian 侧边栏中看到的文件名。 |
file.folder |
Text | 此文件所属文件夹的路径。 |
file.path |
Text | 包含文件名的完整文件路径。 |
file.ext |
Text | 文件类型的扩展名;通常为 md。 |
file.link |
Link | 指向文件的链接。 |
file.size |
Number | 文件的大小(以字节为单位)。 |
file.ctime |
Date with Time | 文件创建的日期(含时间)。 |
file.cday |
Date | 文件创建的日期。 |
file.mtime |
Date with Time | 文件最后修改的日期(含时间)。 |
file.mday |
Date | 文件最后修改的日期。 |
file.tags |
List | 笔记中所有唯一标签的列表。子标签按每个级别进行拆分,因此 #Tag/1/A 将被存储为 [#Tag, #Tag/1, #Tag/1/A]。 |
file.etags |
List | 笔记中所有显式标签的列表;与 file.tags 不同,不会拆分子标签,即 [#Tag/1/A]。 |
file.inlinks |
List | 指向此文件的所有传入链接的列表,意味着所有包含指向此文件的链接的文件。 |
file.outlinks |
List | 从此文件的所有传出链接的列表,意味着文件包含的所有链接。 |
file.aliases |
List | 通过 YAML 前置数据定义的笔记的所有别名的列表。 |
file.tasks |
List | 此文件中所有任务的列表(即 - [ ] 一些任务) |
file.lists |
List | 文件中所有列表元素的列表(包括任务);这些元素实际上是任务,可以在任务视图中呈现。 |
file.frontmatter |
List | 以 key | value 文本值形式包含所有前置数据的原始值;主要用于检查原始前置数据值或动态列出前置数据键。 |
file.day |
Date | 仅在文件名中包含日期(格式为 yyyy-mm-dd 或 yyyymmdd)或具有日期字段/内联字段时可用。 |
file.starred |
Boolean | 如果此文件通过 Obsidian 核心插件“书签”被添加为书签。 |
==file.frontmatter 实际这里是一个对象(object),而不是原始文本,我觉得这里的说明可能是没有更新。在使用时,frontmatter 的属性会直接附加在笔记对象上 note.created,而不需要 note.file.frontmatter.created,当然第二种方法也是可用的。==
示例页面
这是一个简略的 Markdown 页面,其中包含用户定义的添加元数据的两种方法:
---
genre: "action"
reviewed: false
---
# Movie X
#movies
**Thoughts**:: It was decent.
**Rating**:: 6
[mood:: okay] | [length:: 2 hours]除了您在这里看到的值之外,页面还可以使用上述所有键。
查询示例
您可以使用以下查询来查询上述信息的一部分,例如:
```dataview
TABLE file.ctime, length, rating, reviewed
FROM #movies
```任务和列表的元数据(Metadata on Tasks and Lists)
就像页面一样,您还可以在列表项和任务级别添加字段,将其绑定到特定任务作为上下文。为此,您需要使用内联字段语法(【元数据 > 添加元数据 > 如何添加字段? > 内联字段】):
- [ ] Hello, this is some [metadata:: value]!
- [X] I finished this on [completion:: 2021-08-15].任务和列表项在数据上是相同的,因此您所有的项目符号都有这里描述的所有信息。
字段简写
Tasks 插件通过使用 Emoji 引入了一种不同的符号来配置与任务相关的不同日期。在 Dataview 的上下文中,这种符号称为字段简写。当前版本的 Dataview 仅支持如下所示的日期简写,优先级和重复性简写不受支持。
示例
- 本周六到期 🗓️2021-08-29
- 上周六完成 ✅2021-08-22
- 我在 ➕1990-06-14 时完成了
- 我可以在这个周末开始的任务 🛫2021-08-29
- 我提前完成的任务 ⏳2021-08-29 ✅2021-08-22
这些 Emoji 简写有两个特点。首先,它们省略了内联字段语法(不需要 [🗓️:: YYYY-MM-DD]),其次,它们在数据上映射到文本字段名称:
| 字段名称 | 简写语法 |
|---|---|
| due | 🗓️YYYY-MM-DD |
| completion | ✅YYYY-MM-DD |
| created | ➕YYYY-MM-DD |
| start | 🛫YYYY-MM-DD |
| scheduled | ⏳YYYY-MM-DD |
这意味着,如果您想查询所有在 2021-08-22 完成的任务,您可以写:
```dataview
TASK
WHERE completion = date("2021-08-22")
```以下两种书写格式都将被列出:
- [x] Completed last Saturday ✅2021-08-22
- [x] Some Done Task [completion:: 2021-08-22]隐式字段(任务)
与页面一样,Dataview 会向每个任务或列表项添加一些隐式字段:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
status |
Text | 此任务的完成状态,由 [ ] 括号内的字符决定。通常未完成任务为一个空格 " ",已完成任务为 "x",但允许支持替代任务状态的插件。 |
checked |
Boolean | 此任务的状态是否不为空,意味着它在 [ ] 括号内有某个状态字符(可能是 "x" 也可能不是),而不是一个空格。 |
completed |
Boolean | 此特定任务是否已完成;这不考虑任何子任务的完成或未完成。如果任务被标记为 "x",则明确视为“已完成”。如果使用自定义状态,例如 [-],则 checked 为真,而 completed 为假。 |
fullyCompleted |
Boolean | 此任务及其所有子任务是否已完成。 |
text |
Text | 此任务的纯文本,包括任何元数据字段注释。 |
visual |
Text | 此任务的文本,由 Dataview 渲染。此字段可以在 DataviewJS 中被覆盖,以允许渲染不同于常规任务文本的任务文本,同时仍允许勾选任务(因为 Dataview 验证逻辑通常会将文本与文件中的文本进行检查)。 |
line |
Number | 此任务在文件中的行号。 |
lineCount |
Number | 此任务占用的 Markdown 行数。 |
path |
Text | 此任务所在文件的完整路径。与页面的 file.path 相同。 |
section |
Link | 指向此任务所在的部分(章节)的链接。 |
tags |
List | 此任务文本中的所有标签。 |
outlinks |
List | 此任务中定义的所有链接。 |
link |
Link | 指向此任务附近最近的可链接块的链接;用于创建指向该任务的链接。 |
children |
List | 此任务的全部子任务或子列表。 |
task |
Boolean | 如果为真,则这是一个任务;否则,它是一个常规列表元素。 |
annotated |
Boolean | 如果任务文本包含任何元数据字段,则为真;否则为假。 |
parent |
Number | 如果存在,则为此任务上层任务的行号;如果这是根级任务,则为 null。 |
blockId |
Text | 此任务/列表元素的块 ID,如果已使用 ^blockId 语法定义;否则为 null。 |
使用简写语法(【元数据 > 任务和列表的元数据 > 字段简写】)时,以下附加属性可能可用:
completion:任务完成的日期。(真正完成了这个任务的时间)due:任务到期的日期(如果有的话)。(截止时间,类似于 deadline)created:任务创建的日期。(写下这个任务的时间)start:任务可以开始的日期。(真正开始着手去完成这个任务的时间)scheduled:任务计划进行的日期。(计划中的开始时间)
在查询中访问隐式字段
如果您使用的是 TASK 查询(【查询语言参考 > 查询类型 > 任务】),您的任务是顶级信息,可以不带任何前缀地使用:
```dataview
TASK
WHERE !fullyCompleted
```对于其他查询类型,您需要首先访问隐式字段 file.lists 或 file.tasks,以检查这些特定于列表项的隐式字段:
```dataview
LIST
WHERE any(file.tasks, (t) => !t.fullyCompleted)
```这将返回所有包含未完成任务的文件链接。我们在页面级别返回一个任务列表,因此需要使用列表函数(【查询语言参考 > 函数】)(这里好像没有一个确定的函数来匹配这个链接,原文也如此。重点在于理解列表这个类型,至于这个链接……迷)来查看每个元素。
查询语言、JS 和行内查询(DQL, JS and Inlines)
一旦您向相关页面添加了有用的数据(【元数据 > 添加元数据】),您会希望在某处实际显示它或对其进行操作。Dataview 以四种不同的方式实现这一点,所有这些都直接写在您的 Markdown 中的代码块中,并在您的库发生更改时实时重新加载。
Dataview 查询语言 (DQL)
Dataview 查询语言(简称 DQL)(【查询语言参考】)是一种类似 SQL 的语言,也是 Dataview 的核心功能。它支持四种查询类型(【查询语言参考 > 查询类型】)以产生不同的输出,数据命令用于细化、重新排序或分组您的结果,并提供丰富的函数(【查询语言参考 > 函数】),允许进行多种操作和调整,以实现您想要的输出。
如果您熟悉 SQL,请阅读《与 SQL 的区别》(【查询语言参考 > 与 SQL 的差异】),以避免将 DQL 与 SQL 混淆。
您可以使用类型为 dataview 的代码块来创建 DQL 查询:
```dataview
TABLE rating AS "Rating", summary AS "Summary" FROM #games
SORT rating DESC
```一个有效的代码块需要在开始和结束时使用反引号(`)各三个。不要将反引号与外观相似的单引号(')混淆!
在查询语言参考(【查询语言参考】)中查找如何编写 DQL 查询的说明。如果您喜欢通过示例学习,请查看查询示例(【问答和资源 > 示例】)。
内联 DQL
内联 DQL 使用内联块格式而不是代码块,并使用可配置的前缀将此内联代码块标记为 DQL 块。
= this.file.name
您可以在 Dataview 的设置(“代码块设置”——“内联查询前缀”)中更改 "=" 为其他标记(如 dv: 或 ~)。
内联 DQL 查询会在您的笔记中间的某个位置精确显示一个值。它们与您笔记的内容无缝融合:
Today is `= date(today)` - `= [[exams]].deadline - date(today)` until exams!例如,将渲染为:
Today is November 07, 2022 - 2 months, 5 days until exams!内联 DQL 不能查询多个页面。它们总是精确显示一个值,而不是值的列表(或表格)。您可以通过前缀 this. 访问当前页面的属性,或通过 [[linkToPage]] 访问其他页面。
`= this.file.name`
`= this.file.mtime`
`= this.someMetadataField`
`= [[secondPage]].file.name`
`= [[secondPage]].file.mtime`
`= [[secondPage]].someMetadataField`您可以在内联 DQL 查询中使用所有可用的表达式(【查询语言参考 > 表达式】)和字面量(【查询语言参考 > 字面量】),包括函数(【查询语言参考 > 函数】)。另一方面,查询类型和数据命令在内联中不可用。
Assignment due in `= this.due - date(today)`
Final paper due in `= [[Computer Science Theory]].due - date(today)`
🏃♂️ Goal reached? `= choice(this.steps > 10000, "YES!", "**No**, get moving!")`
You have `= length(filter(link(dateformat(date(today), "yyyy-MM-dd")).file.tasks, (t) => !t.completed))` tasks to do. `= choice(date(today).weekday > 5, "Take it easy!", "Time to get work done!")`Dataview JS
Dataview JavaScript API (【JavaScript 查询参考】)赋予您完整的 JavaScript 功能,并提供了一种 DSL(领域特定语言)来提取 Dataview 数据和执行查询,使您能够创建任意复杂的查询和视图。与查询语言类似,您通过带有 dataviewjs 注释的代码块创建 Dataview JS 块:
```dataviewjs
let pages = dv.pages("#books and -#books/finished").where(b => b.rating >= 7);
for (let group of pages.groupBy(b => b.genre)) {
dv.header(3, group.key);
dv.list(group.rows.file.name);
}
```在 JS Dataview 块内,您可以通过 dv 变量访问完整的 Dataview API。有关您可以做什么的说明,请参阅 API 文档(【JavaScript 查询参考 > 代码块参考】)或 API 示例(【JavaScript 查询参考 > 代码块示例】)。
编写 JavaScript 查询是一种高级技术,需要对编程和 JavaScript 有一定的理解。请注意,JavaScript 查询可以访问您的文件系统,在使用他人的 JavaScript 查询时要小心,特别是当它们没有通过 Obsidian 社区公开分享时。(写好不容易,但把所有文档搞得面目全非好像并不复杂。)
内联 Dataview JS
与查询语言类似,您可以编写 JS 内联查询,这使您能够直接嵌入计算得出的 JS 值。您可以通过内联代码块创建 JS 内联查询:
`$= dv.current().file.mtime`在内联 DataviewJS 中,您可以访问 dv 变量,与 dataviewjs 代码块相同,并可以进行所有相同的调用。结果应该是一个可评估为 JavaScript 值的内容,Dataview 会自动适当地渲染它。
与内联 DQL 查询不同,内联 JS 查询可以访问 Dataview JS 查询所提供的所有内容,因此可以查询和输出多个页面。
您可以在 Dataview 的设置中(“代码块设置”——“JavaScript 内联查询前缀”)将 $= 更改为其他标记(如 dvjs: 或 $~)。
查询语言参考(Query Language Reference)
结构化查询(Structure of a Query)
Dataview 提供了多种方式(【查询语言、JS 和行内查询】)来编写查询,语法各不相同。
本页面提供有关如何编写 Dataview 查询语言(DQL)查询的信息。如果您对如何编写内联查询感兴趣,请参阅 DQL、JS 和内联的内联部分(【查询语言、JS 和行内查询】)。您可以在 JavaScript 参考(【JavaScript 查询参考】)中找到有关 JavaScript 查询的更多信息。
DQL 是一种类似 SQL 的查询语言,用于对您的数据创建不同的视图或计算。它支持:
- 选择输出格式(查询类型(【查询语言参考 > 查询类型】))
- 从特定来源(【查询语言参考 > 来源】)获取页面(笔记),即通过标签、文件夹或链接进行筛选
- 通过对字段进行简单操作(如比较、存在性检查等)过滤页面/数据
- 转换字段以进行显示,即通过计算或拆分多值字段
- 根据字段排序结果
- 根据字段分组结果
- 限制结果数量
如果您熟悉 SQL,请阅读《与 SQL 的区别》(【查询语言参考 > 与 SQL 的差异】),以避免将 DQL 与 SQL 混淆。
让我们看看如何使用 DQL。
DQL 查询的一般格式
每个查询遵循相同的结构,由以下部分组成:
- 恰好一个查询类型,具有零个、一个或多个字段(【元数据 > 添加元数据】),具体取决于查询类型
- 零个或一个 FROM 数据命令,具有一个或多个来源(【查询语言参考 > 来源】)
- 零个到多个其他数据命令,具有一个或多个表达式(【查询语言参考 > 表达式】)和/或其他信息,具体取决于数据命令
从高层次来看,查询符合以下模式:
```dataview
<查询类型> <字段>
FROM <源>
<数据命令> <表达式>
<数据命令> <表达式>
...
```以下部分将进一步详细解释理论。
选择输出格式
查询的输出格式由其查询类型决定。可用的查询类型有四种:
- TABLE:结果的表格,每个结果一行,具有一个或多个字段数据列。(以表格形式显示查询结果)
- LIST:匹配查询的页面的项目符号列表。您可以为每个页面输出一个字段及其文件链接。(以无序列表形式显示查询结果)
- TASK:与给定查询匹配的交互式任务列表。(以任务列表形式显示查询结果,并可进行交互,就是可以勾选任务)
- CALENDAR:日历视图,通过点在其对应日期上显示每个结果。(将查询结果显示在日历中的对应日期上)
查询类型是查询中唯一必需的命令,其他内容都是可选的。
根据您的库的大小,执行以下示例可能会耗时较长,甚至在极端情况下导致 Obsidian 冻结。建议您指定一个 FROM,以限制查询执行到库文件的特定子集。请参见下一部分。
以无序列表形式显示你保险库中的所有页面
```dataview
LIST
```
列出你保险库中所有的任务,无论是否完成
```dataview
TASK
```
渲染一个日历视图,每个页面在其创建日期上以点的形式表示。
```dataview
CALENDAR file.cday
```
显示一个表格,包含您库中的所有页面、它们的到期字段值、文件标签以及多值字段工作时间的平均值。
```dataview
TABLE due, file.tags AS "tags", average(working-hours)
```选择数据源
除了查询类型之外,您还有多个数据命令可用,帮助您限制、细化、排序或分组查询。其中一个查询命令是 FROM 语句。FROM 接受一个来源或多个来源(【查询语言参考 > 来源】)的组合作为参数,并将查询限制为与您的来源匹配的一组页面。
它的行为与其他数据命令不同:您可以在查询的查询类型后添加零个或一个 FROM 数据命令。您不能添加多个 FROM 语句,也不能在其他数据命令之后添加它。
列出文件夹 Books 及其子文件夹中的所有页面。
```dataview
LIST
FROM "Books"
```
Lists all pages that include the tag `#status/open` or `#status/wip`
```dataview
LIST
FROM #status/open OR #status/wip
```
列出所有具有标签 `#assignment` 且位于文件夹 "30 School"(或其子文件夹)中的页面,或者位于文件夹 "30 School/32 Homeworks" 中并在页面 School Dashboard Current To Dos 上链接的页面。
```dataview
LIST
FROM (#assignment AND "30 School") OR ("30 School/32 Homeworks" AND outgoing([[School Dashboard Current To Dos]]))
```FROM 的信息。(暂时没有链接)过滤、排序、分组或限制结果
除了上述解释的查询类型和数据命令 FROM,您还有其他多个数据命令可用,帮助您限制、细化、排序或分组查询结果。
除了 FROM 命令外,所有数据命令都可以多次使用,顺序不限(只要它们位于查询类型和 FROM 之后,如果使用了 FROM)。它们将按照书写顺序执行。
可用的命令有:
- FROM:如上所述(【查询语言参考 > 结构化查询 > 选择数据源】)。
- WHERE:根据笔记中的信息和元数据字段过滤笔记。
- SORT:根据字段和方向对结果进行排序。
- GROUP BY:将多个结果汇总为每组一个结果行。
- LIMIT:将查询结果的数量限制为给定的数字。
- FLATTEN:根据字段或计算将一个结果拆分为多个结果。
列出所有具有元数据字段 `due` 且 `due` 在今天之前的页面。
```dataview
LIST
WHERE due AND due < date(today)
```
列出您库中最近创建的 10 个具有标签 `#status/open` 的页面。
```dataview
LIST
FROM #status/open
SORT file.ctime DESC
LIMIT 10
```
列出您库中 10 个最旧且未完成的任务,作为一个互动任务列表,按其所在文件分组,并从旧到新排序。
```dataview
TASK
WHERE !completed
SORT created ASC
LIMIT 10
GROUP BY file.link
SORT rows.file.ctime ASC
```示例(查询)
以下是一些示例查询。在这里可以找到更多示例(【问答和资源 > 示例】)。
```dataview
TASK
``````dataview
TABLE recipe-type AS "type", portions, length
FROM #recipes
``````dataview
LIST
FROM #assignments
WHERE status = "open"
```
````md
```dataview
TABLE file.ctime, appointment.type, appointment.time, follow-ups
FROM "30 Protocols/32 Management"
WHERE follow-ups
SORT appointment.time
``````dataview
TABLE L.text AS "My lists"
FROM "dailys"
FLATTEN file.lists AS L
WHERE contains(L.author, "Surname")
``````dataview
LIST rows.c
WHERE typeof(contacts) = "array" AND contains(contacts, [[Mr. L]])
SORT length(contacts)
FLATTEN contacts as c
SORT link(c).age ASC
```查询类型(Query Types)
查询类型决定了您的 Dataview 查询的输出格式。它是您提供给 Dataview 查询的第一个也是唯一的强制性规范。可用的查询类型有四种:LIST、TABLE、TASK 和 CALENDAR。
查询类型还决定了查询执行的信息级别。LIST、TABLE 和 CALENDAR 在页面级别操作,而 TASK 查询在文件.tasks 级别操作。有关更多信息,请参阅 TASK 查询类型。
您可以将每种查询类型与所有可用的数据命令(【查询语言参考 > 数据命令】)结合使用,以细化结果集。有关查询类型和数据命令之间相互关系的更多信息,请参阅如何使用 Dataview (【总览 > 如何使用 Dataview】)和结构页面(【查询语言参考 > 结构化查询】)。
查询类型决定了查询的输出格式。它是查询的唯一必须信息。
列表(LIST)
LIST 查询输出一个项目符号列表,包含您的文件链接或组名称(如果您选择了分组(【查询语言参考 > 数据命令 > GROUP BY】))。您可以指定最多一条附加信息与您的文件或组信息一起输出。
LISTLIST 输出一个页面链接或组键的项目符号列表。您可以为每个结果指定一条附加信息进行显示。
最简单的 LIST 查询输出您库中所有文件的项目符号列表:
```dataview
LIST
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- Classic Cheesecake
- Git Basics
- How to fix Git Cheatsheet
- League of Legends
- Pillars of Eternity 2
- Stardew Valley
- Dashboard
但您当然可以使用数据命令(【查询语言参考 > 数据命令】)来限制要列出哪些页面:
```dataview
LIST
FROM #games/mobas OR #games/crpg
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
输出附加信息
要向您的查询添加附加信息,请在 LIST 命令之后、可能可用的数据命令之前指定该信息:
```dataview
LIST file.folder
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- Classic Cheesecake: Baking/Recipes
- Git Basics: Coding
- How to fix Git Cheatsheet: Coding/Cheatsheets
- League of Legends: Games
- Pillars of Eternity 2: Games
- Stardew Valley: Games/finished
- Dashboard:
您只能添加一个附加信息,而不能添加多个。但是,您可以指定一个计算值,而不是简单的元数据字段,这可以包含多个字段的信息:
```dataview
LIST "File Path: " + file.folder + " _(created: " + file.cday + ")_"
FROM "Games"
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- League of Legends: File Path: Games (created: May 13, 2021)
- Pillars of Eternity 2: File Path: Games (created: Februrary 02, 2022)
- Stardew Valley: File Path: Games/finished (created: April 04, 2021)
分组
默认情况下,分组列表仅显示它们的组键(分组名称)。
```dataview
LIST
GROUP BY type
```输出
- game
- knowledge
- moc
- recipe
- summary
在分组 LIST 查询中,一个常见的用例是通过将文件链接指定为附加信息来添加到输出中:
```dataview
LIST rows.file.link
GROUP BY type
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- game:
- knowledge:
- moc:
- recipe:
- summary:
无 ID 列表
如果您不想在列表视图中包含文件名或组键,可以使用 LIST WITHOUT ID。LIST WITHOUT ID 的工作方式与 LIST 相同,但如果您添加了附加信息,它不会输出文件链接或组名称。
```dataview
LIST WITHOUT ID
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- Classic Cheesecake
- Git Basics
- How to fix Git Cheatsheet
- League of Legends
- Pillars of Eternity 2
- Stardew Valley
- Dashboard
因为它不包含附加信息,所以与 LIST 是一样的!
```dataview
LIST WITHOUT ID type
```输出(每个文件的类型,但是因为无 ID,所以没输出文件的链接,就光剩下类型了)
- moc
- recipe
- summary
- knowledge
- game
- game
- game
如果您想输出计算值,LIST WITHOUT ID 会很方便。
```dataview
LIST WITHOUT ID length(rows) + " pages of type " + key
GROUP BY type
```输出
- 3 pages of type game
- 1 pages of type knowledge
- 1 pages of type moc
- 1 pages of type recipe
- 1 pages of type summary
表格(TABLE)
TABLE 查询类型以表格视图输出页面数据。您可以通过将零到多个元数据字段作为逗号分隔的列表添加到您的 TABLE 查询中。不仅可以使用普通的元数据字段作为列,还可以指定计算。可选地,您可以通过 AS <header> 语法指定表头。与所有其他查询类型一样,您可以使用数据命令(【查询语言参考 > 数据命令】)来细化查询的结果集。
TABLE 查询以表格形式呈现任意数量的元数据值或计算。可以通过 AS <header> 指定列标题。
```dataview
TABLE
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| File (7) |
|---|
| Classic Cheesecake |
| Git Basics |
| How to fix Git Cheatsheet |
| League of Legends |
| Pillars of Eternity 2 |
| Stardew Valley |
| Dashboard |
您可以通过 Dataview 设置中的表格设置 -> 主列名称 / 组列名称来更改第一个列标题的名称(默认是“File”或“Group”)。如果您只想为一个特定的 TABLE 查询更改名称,请查看 TABLE WITHOUT ID。
第一列始终显示结果计数。如果您不想显示它,可以在 Dataview 的设置中禁用(“显示结果计数”,自 0.5.52 版本起可用)。
当然,TABLE 是用于指定一个到多个附加信息的。
```dataview
TABLE started, file.folder, file.etags
FROM #games
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| File (3) | started | file.folder | file.etags |
|---|---|---|---|
| League of Legends | May 16, 2021 | Games | - #games/moba |
| Pillars of Eternity 2 | April 21, 2022 | Games | - #games/crpg |
| Stardew Valley | April 04, 2021 | Games/finished | - #games/simulation |
想了解 file.folder 和 file.etags 吗?请在隐式字段页面上(【元数据 > 页面元数据 > 隐式字段】)了解更多关于隐式字段的信息。
自定义列标题
您可以使用 AS 语法为您的列指定自定义标题:
```dataview
TABLE started, file.folder AS Path, file.etags AS "File Tags"
FROM #games
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| File (3) | started | Path | File Tags |
|---|---|---|---|
| League of Legends | May 16, 2021 | Games | - #games/moba |
| Pillars of Eternity 2 | April 21, 2022 | Games | - #games/crpg |
| Stardew Valley | April 04, 2021 | Games/finished | - #games/simulation |
如果您想使用带空格的自定义标题,例如 File Tags,您需要将其用双引号括起来:"File Tags"。
当您想将计算或表达式用作列值时,这尤其有用:
```dataview
TABLE
default(finished, date(today)) - started AS "Played for",
file.folder AS Path,
file.etags AS "File Tags"
FROM #games
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| File (3) | Played for | Path | File Tags |
|---|---|---|---|
| League of Legends | 1 years, 6 months, 1 weeks | Games | - #games/moba |
| Pillars of Eternity 2 | 7 months, 2 days | Games | - #games/crpg |
| Stardew Valley | 4 months, 3 weeks, 3 days | Games/finished | - #games/simulation |
了解更多关于在表达式(【查询语言参考 > 表达式】)和函数(【查询语言参考 > 函数】)下计算表达式和计算的能力。
无 ID 表格
如果您不想要第一列(默认是“文件”或“组”),可以使用 TABLE WITHOUT ID。TABLE WITHOUT ID 的工作方式与 TABLE 相同,但如果您添加额外信息,它不会将文件链接或组名称作为第一列输出。
例如,如果您输出其他识别值,可以使用这个功能:
TABLE WITHOUT ID
steamid,
file.etags AS "File Tags"
FROM #games输出
| steamid (3) | File Tags |
|---|---|
| 560130 | - #games/crog |
| - | - #games/moba |
| 413150 | - #games/simulation |
如果您想为一个特定查询重命名第一列,也可以使用 TABLE WITHOUT ID。
```dataview
TABLE WITHOUT ID
file.link AS "Game",
file.etags AS "File Tags"
FROM #games
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| Game (3) | File Tags |
|---|---|
| League of Legends | - #games/moba |
| Pillars of Eternity 2 | - #games/crpg |
| Stardew Valley | - #games/simulation |
如果您想在所有情况下重命名第一列,请在 Dataview 设置中的表格设置中更改名称。
任务(TASK)
TASK 查询输出您库中所有匹配给定数据命令(【查询语言参考 > 数据命令】)(如果有)的任务的互动列表。与其他查询类型相比,TASK 查询是特殊的,因为它们返回的是任务而不是页面。这意味着所有数据命令(【查询语言参考 > 数据命令】)在任务级别上操作,使您能够细致地过滤任务,例如按状态或任务本身指定的元数据进行过滤。
此外,TASK 查询是通过 DQL 操作文件的唯一方式。通常, Dataview 不会触及文件的内容;然而,如果您通过 Dataview 查询勾选一个任务,它也会在其原始文件中被勾选。在 Dataview 设置中的“任务设置”下,您可以选择在 Dataview 中勾选任务时自动设置完成元数据字段。请注意,这仅在您在 Dataview 块内检查任务时有效。
TASK 查询类型TASK 查询呈现您库中所有任务的互动列表。TASK 查询在任务级别上执行,而非页面级别,允许任务特定的过滤。这是 Dataview 中唯一一个在交互时修改原始文件的命令。
```dataview
TASK
```输出
- Buy new shoes #shopping
- Mail Paul about training schedule
- Finish the math assignment
- Finish Paper 1 [due:: 2022-08-13]
- Read again through chapter 3 [due:: 2022-09-01]
- Write a cheatsheet [due:: 2022-08-02]
- Write a summary of chapter 1-4 [due:: 2022-09-12]
- Hand in physics
- Get new pillows for mom #shopping
- Buy some working pencils #shopping
您可以像使用其他查询类型一样使用数据命令(【查询语言参考 > 数据命令】)。数据命令在任务级别上执行,使任务上的隐式字段(【元数据 > 任务和列表的元数据 > 隐式字段】)直接可用。
```dataview
TASK
WHERE !completed AND contains(tags, "#shopping")
```输出
- Buy new shoes #shopping
- Get new pillows for mom #shopping
任务的一个常见用例是按其来源文件对任务进行分组:
```dataview
TASK
WHERE !completed
GROUP BY file.link
```输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
2022-07-30 (1)
- Finish the math assignment
- Read again through chapter 3 [due:: 2022-09-01]
- Write a summary of chapter 1-4 [due:: 2022-09-12]
2022-09-21 (2)
- Buy new shoes #shopping
- Mail Paul about training schedule
2022-09-27 (1)
- Get new pillows for mom #shopping
注意到 2022-07-30 表头上的 (1) 吗?子任务属于其父任务,不单独计数。此外,它们在过滤时的行为也不同。
子任务
如果一个任务通过制表符缩进并位于未缩进任务下方,则该任务被视为子任务。
- clean up the house
- kitchen
- living room
- Bedroom [urgent:: true]
虽然在项目符号列表项下缩进的任务严格来说也是子任务,但在大多数情况下,Dataview 会将它们视为普通任务处理。
子任务属于其父任务。这意味着如果您查询任务,子任务会作为其父任务的一部分返回。
```dataview
TASK
```输出
- clean up the house
- kitchen
- living room
- Bedroom [urgent:: true]
- Call the insurance about the car
- Find out the transaction number
这特别意味着,只要父任务匹配查询,子任务就会成为结果集的一部分——即使子任务本身不匹配。
```dataview
TASK
WHERE !completed
```输出
- clean up the house
- kitchen
- living room
- Bedroom [urgent:: true]
- Call the insurance about the car
在这里,living room 虽然不匹配查询,但仍然被包含在内,因为它的父任务 clean up the house 是匹配的。
请注意,如果子任务匹配您的条件但父任务不匹配,您将会得到单独的子任务返回。
```dataview
TASK
WHERE urgent
```输出
- Bedroom [urgent:: true]
日历(CALENDAR)
CALENDAR 查询输出一个基于月份的日历,每个结果以点的形式显示在相应的日期上。CALENDAR 是唯一需要额外信息的查询类型。这些额外信息需要是所有查询页面上的日期(【元数据 > 数据类型 > 可用字段类型 > 日期】)(或未设置)。
CALENDAR 查询类型CALENDAR 查询类型呈现一个日历视图,每个结果通过给定元数据字段日期上的点来表示。
```dataview
CALENDAR file.ctime
```输出
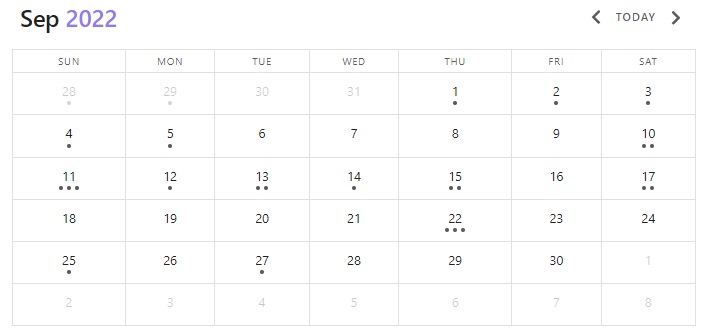
虽然可以将 SORT 和 GROUP BY 与 CALENDAR 结合使用,但这没有效果。此外,如果给定的元数据字段包含有效日期(【元数据 > 数据类型 > 可用字段类型 > 日期】)以外的内容,日历查询将不会渲染(但字段可以为空)。为了确保您只考虑有效页面,您可以过滤有效的元数据值:
```dataview
CALENDAR due
WHERE typeof(due) = "date"
```数据命令(Data Commands)
Dataview 查询可以由多个命令组成。命令按顺序执行,您可以重复使用命令(例如,可以有多个 WHERE 块或多个 GROUP BY 块)。
FROM(来源)
FROM 语句确定最初将收集哪些页面,并将其传递给其他命令以进行进一步过滤。您可以从任何来源(【查询语言参考 > 来源】)选择,可以按文件夹、按标签或按传入/传出链接进行选择。
- 标签:要从某个标签(及其所有子标签)中选择,使用
FROM #tag。 - 文件夹:要从某个文件夹(及其所有子文件夹)中选择,使用
FROM "folder"。 - 单个文件:要从单个文件中选择,使用
FROM "path/to/file"。 - 链接:您可以选择链接到某个文件的链接,或从某个文件的所有链接。
- 要获取所有链接到
[[note]]的页面,使用FROM [[note]]。 - 要获取所有链接自
[[note]]的页面(即该文件中的所有链接),使用FROM outgoing([[note]])。
- 要获取所有链接到
您可以组合这些过滤器,以使用 and 和 or 获取更高级的来源。
- 例如,
#tag and "folder"将返回文件夹中所有带有#tag的页面。 [[Food]] or [[Exercise]]将返回任何链接到[[Food]]或[[Exercise]]的页面。
您还可以“否定”来源,以获取任何不匹配某个来源的内容,使用 -:
-#tag将排除具有该标签的文件。#tag and -"folder"将仅包括标签为#tag,且不在"folder"中的文件。
WHERE(过滤)
根据字段过滤页面。只有在条件为真时,才会返回页面。
WHERE <条件>- 获取过去 24 小时内修改的所有文件:
LIST WHERE file.mtime >= date(today) - dur(1 day)- 查找所有未标记为完成且超过一个月的项目:
LIST FROM #projects
WHERE !completed AND file.ctime <= date(today) - dur(1 month)SORT(排序)
按一个或多个字段对所有结果进行排序。
SORT date [ASCENDING/DESCENDING/ASC/DESC]您还可以指定多个字段进行排序。排序将基于第一个字段进行。如果出现平局,将使用第二个字段对平局的字段进行排序。如果仍然平局,第三个字段将解决此问题,以此类推。
SORT field1 [ASCENDING/DESCENDING/ASC/DESC], ..., fieldN [ASC/DESC]GROUP BY(分组)
按字段对所有结果进行分组。每个唯一字段值对应一行,具有两个属性:一个对应于被分组的字段,另一个是包含所有匹配页面的 rows 数组字段。
GROUP BY field
GROUP BY (computed_field) AS name为了方便处理 rows 数组,Dataview 支持字段“调换”。如果您想从 rows 数组中的每个对象获取字段 test,则 rows.test 将自动从 rows 中的每个对象提取 test 字段,生成一个新数组。然后,您可以对结果数组应用聚合操作符,如 sum() 或 flat()。
FLATTEN(扁平化)
在每一行中展平一个数组,使数组中的每个条目产生一个结果行。
FLATTEN field
FLATTEN (computed_field) AS name例如,将每个文献笔记中的作者字段扁平化,以便每个作者对应一行:
TABLE authors FROM #LiteratureNote
FLATTEN authors输出
| File | authors |
|---|---|
| stegEnvironmentalPsychologyIntroduction2018 SN | Steg, L. |
| stegEnvironmentalPsychologyIntroduction2018 SN | Van den Berg, A. E. |
| stegEnvironmentalPsychologyIntroduction2018 SN | De Groot, J. I. M. |
| Soap Dragons SN | Robert Lamb |
| Soap Dragons SN | Joe McCormick |
| smithPainAssaultSelf2007 SN | Jonathan A. Smith |
| smithPainAssaultSelf2007 SN | Mike Osborn |
一个好的使用场景是当有一个深度嵌套的列表时,您希望更方便地使用。例如,file.lists 或 file.tasks。请注意,虽然最终结果略有不同(分组与非分组),但为了查询更简单。您可以使用 GROUP BY file.link 来获得相同的结果,但需要使用 rows.T.text,如前所述。
table T.text as "Task Text"
from "Scratchpad"
flatten file.tasks as T
where T.texttable filter(file.tasks.text, (t) => t) as "Task Text"
from "Scratchpad"
where file.tasks.textFLATTEN 使得操作嵌套列表变得更加简单,因为您可以对它们使用更简单的条件,而不是使用像 map() 或 filter() 这样的函数。(我个人觉得这套查询语言更加晦涩了,想弄懂需要点编程基础,可是有了编程基础为什么不用更灵活也有更多资料的 JS 呢?)
LIMIT(限制数量)
将结果限制为最多 N 个值。
LIMIT 5命令按书写顺序处理,因此以下内容是在已经限制结果后进行排序:
LIMIT 5
SORT date ASCENDING(两行顺序调换就是先排序,再限制)
与 SQL 的差异(Differences to SQL)
如果您熟悉 SQL 并且在编写 SQL 查询方面有经验,您可能会以类似的方式编写 DQL 查询。然而,DQL 与 SQL 有显著不同。
DQL 查询是从上到下逐行执行的。它更像是一段计算机程序,而不是典型的 SQL 查询。
当一行被评估时,它会生成一个结果集,并将整个集合传递给下一行 DQL,后者将处理从前一行接收到的集合。这就是为什么在 DQL 中,例如可以有多个 WHERE 子句。但在 DQL 中,它不是一个“子句”,而是一个“数据命令”。 DQL 查询的每一行(除了第一行和第二行)都是一个“数据命令”。
DQL 查询的结构
DQL 查询不是以 SELECT 开头,而是以一个确定查询类型的词开头,这决定了最终结果在屏幕上的呈现方式(表格、列表、任务列表或日历)。接下来是字段列表,这实际上与 SELECT 语句后面的列列表非常相似。
下一行以 FROM 开头,后面不是表名,而是一个复杂表达式,类似于 SQL 的 WHERE 子句。在这里,您可以对许多内容进行过滤,如文件中的标签、文件名、路径名等。在后台,此命令已经生成了一个结果集,这将是我们在后续行中通过“数据命令”(【查询语言参考 > 数据命令】)进行进一步数据处理的初始集。
您可以根据需要添加任意数量的后续行。每一行都将以数据命令开头,并重新塑造从前一行接收到的结果集。例如:
WHERE数据命令将仅保留结果集中符合给定条件的行。这意味着,除非结果集中的所有数据都符合条件,否则该命令将传递给下一行的结果集将比从前一行接收到的结果集更小。与 SQL 不同,您可以使用任意数量的WHERE命令。FLATTEN数据命令在常见 SQL 中不存在,但在 DQL 中,您可以使用它来减少结果集的深度。- DQL 与 SQL 类似,具有
GROUP BY命令,但这一命令可以多次使用,这在常见 SQL 中是不可能的。您甚至可以连续执行多个SORT或GROUP BY命令。
来源(Sources)
Dataview 源是指识别一组文件、任务或其他数据的内容。源在 Dataview 内部被索引,因此查询速度很快。源的最主要用途是 FROM 数据命令(【查询语言参考 > 数据命令 > FROM】)。它们也用于各种 JavaScript API 查询调用中。
来源类型
Dataview 目前支持四种源类型。
标签
源的形式为 #tag。这将匹配具有给定标签的所有文件/章节/任务。
```dataview
LIST
FROM #homework
```文件夹
源的形式为 "Folder"。这将匹配给定文件夹及其子文件夹中包含的所有文件/章节/任务。需要提供完整的库路径,而不仅仅是文件夹名称。请注意,不支持尾部斜杠,即 "Path/To/Folder/" 将无法使用,但 "Path/To/Folder" 可以。
```dataview
TABLE file.ctime, status
FROM "projects/brainstorming"
```特定文件
您可以通过指定完整路径来选择特定文件:"folder/File"。
- 如果您有一个文件和一个路径完全相同的文件夹,Dataview 会优先选择文件夹。您可以通过指定扩展名来强制它读取文件:
folder/File.md。
```dataview
LIST WITHOUT ID next-in-line
FROM "30 Hobbies/Games/Dashboard"
```内链/外链
您可以选择链接到某个文件,或从某个文件出来的所有链接。
- 要获取所有链接到
[[note]]的页面,请使用[[note]]。 - 要获取所有从
[[note]]链接的页面(即该文件中的所有链接),请使用outgoing([[note]])。 - 您可以通过
[[#]]或[[]]隐式引用当前文件,即[[]]让您查询所有链接到当前文件的文件。
```dataview
LIST
FROM [[]]
```
```dataview
LIST
FROM outgoing([[Dashboard]])
```组合来源
您可以组合这些过滤器,以使用 and 和 or 获取更高级的源。
- 例如,
#tag and "folder"将返回文件夹中所有带有#tag的页面。 - 查询
#food and !#fastfood只会返回包含#food但不包含#fastfood的页面。(==和前文矛盾,前面说的使用-表示否定,这里遵照原始文档,请自行测试==) [[Food]] or [[Exercise]]将返回链接到[[Food]]或[[Exercise]]的任何页面。
如果您有复杂的查询,其中分组或优先级很重要,可以使用括号进行逻辑分组:
#tag and ("folder" or #other-tag)(#tag1 or #tag2) and (#tag3 or #tag4)
表达式(Expressions)
Dataview 查询语言表达式是指任何可以产生值的内容:
- 所有字段(【元数据】)
- 所有字面量(【查询语言参考 > 字面量】)
- 以及计算值,如
field - 9或函数调用(【查询语言参考 > 函数】)。
基本上,所有不是查询类型(【查询语言参考 > 查询类型】)或数据命令(【查询语言参考 > 数据命令】)的内容都是表达式。
以下内容在 DQL 中被视为表达式:
# 字面量
1 (数字)
true/false (布尔值)
"text" (文本)
date(2021-04-18) (日期)
dur(1 day) (持续时间)
[[Link]] (链接)
[1, 2, 3] (列表)
{ a: 1, b: 2 } (对象)
# Lambda(匿名函数)
(x1, x2) => ... (lambda)
# 引用
field (直接引用字段)
simple-field (引用包含空格/标点的字段,如 "Simple Field!")
a.b (如果 a 是一个对象,获取名为 'b' 的字段)
a[expr] (如果 a 是一个对象或数组,获取由表达式 'expr' 指定的字段)
f(a, b, ...) (调用名为 `f` 的函数,参数为 a, b, ...)
# 算术
a + b (加法)
a - b (减法)
a * b (乘法)
a / b (除法)
a % b (取模/除法的余数)
# 比较
a > b (检查 a 是否大于 b)
a < b (检查 a 是否小于 b)
a = b (检查 a 是否等于 b)
a != b (检查 a 是否不等于 b)
a <= b (检查 a 是否小于或等于 b)
a >= b (检查 a 是否大于或等于 b)
# 字符串
a + b (字符串拼接)
a * num (将字符串重复 <num> 次)
# 特殊操作
[[Link]].value (从页面 `Link` 获取 `value`)接下来是每个内容的更详细解释。
表达式类型
字段作为表达式
最简单的表达式是直接引用字段的表达式。如果您有一个名为 "duedate" 的字段,那么您可以通过名称直接引用它—— duedate。
```dataview
TABLE duedate, class, field-with-space
```如果字段名称包含空格、标点或其他非字母/数字字符,则可以使用 Dataview 的简化名称进行引用,该名称全部为小写,空格替换为 -。例如,"this is a field" 变为 "this-is-a-field";"Hello!" 变为 "hello",依此类推。有关更多信息,请参阅字段名称(【元数据 > 添加元数据 > 字段名称】)。
字面量
常量值: 像 1 或 "hello" 或 date(som) ("月初") 这样的东西。Dataview 支持每种数据类型的字面量;在这里了解更多信息(【查询语言参考 > 字面量】)。
```dataview
LIST
WHERE file.name = "Scribble"
```算术
您可以使用标准算术运算符来组合字段:加法 (+)、减法 (-)、乘法 (*) 和除法 (/)。例如,field1 + field2 是一个表达式,它计算这两个字段的和。
```dataview
TABLE start, end, (end - start) - dur(8 h) AS "Overtime"
FROM #work
```
```dataview
TABLE hrs / 24 AS "days"
FROM "30 Projects"
```比较
您可以使用各种比较运算符比较大多数值:<、>、<=、>=、=、!=。这会产生一个布尔值 true 或 false,可用于查询中的 WHERE 块。
```dataview
LIST
FROM "Games"
WHERE price > 10
```
```dataview
TASK
WHERE due <= date(today)
```
```dataview
LIST
FROM #homework
WHERE status != "done"
```不同数据类型之间的比较可能会导致意想不到的结果。以第二个例子为例:如果 due 没有设置(在页面或任务级别上都没有),它是 null,而 null <= date(today) 返回 true,这> 包括没有到期日期的任务。如果不希望这样,请添加类型检查,以确保您始终比较相同的类型:
```dataview
TASK
WHERE typeof(due) = "date" AND due <= date(today)
```通常,通过 WHERE due AND due <= date(today) 检查元数据是否可用就足够了,但检查类型是获得可预见结果的更安全方法。
列表/对象索引
您可以通过索引运算符 list[<index>] 从列表/数组(【元数据 > 数据类型 > 可用字段类型 > 列表】)中检索数据,其中 <index> 是任何计算表达式。列表索引是 0 开头的,因此第一个元素是索引 0,第二个元素是索引 1,依此类推。例如,list("A", "B", "C")[0] = "A"。
类似的表示法适用于对象(【元数据 > 数据类型 > 可用字段类型 > 对象】)。您可以使用 field["nestedfield"] 来引用对象内部或其他类似嵌套的字段。例如,在下面定义的 YAML 中,我们可以通过 episode_metadata["previous"] 引用 previous。
---
aliases:
- "ABC"
current_episode: "S01E03"
episode_metadata:
previous: "S01E02"
next: "S01E04"
---您还可以通过索引运算符从对象中检索数据(对象将文本映射到数据值),此时索引为“字符串/文本”而不是数字。您还可以使用简写形式 object.<name>,其中 <name> 是要检索的值的名称。对于之前的 frontmatter 示例,我们也可以使用 episode_metadata.previous 来获取相同的值。
索引表达式也适用于那些查询语言不直接支持的字段的对象。一个好的例子是 where,因为它是一个关键字。如果您的 frontmatter/metadata 包含一个名为 where 的字段,您可以通过行语法引用它:row["where"]。有关更多信息,请查看常见问题中的说明(【问答和资源 > 常见问题解答】)和相应的讨论。
```dataview
TABLE id, episode_metadata.next, aliases[0]
```函数调用
Dataview 支持多种用于数据操作的函数,具体内容在函数文档中有详细描述(【查询语言参考 > 函数】)。它们的一般语法为 function(arg1, arg2, ...),例如 lower(file.name) 或 regexmatch("A.+", file.folder)。
```dataview
LIST
WHERE contains(file.name, "WIP")
```
```dataview
LIST
WHERE string(file.day.year) = split(this.file.name, "-W")[0]
```Lambdas
Lambda 是一种高级字面量,允许您定义一个接受若干输入并产生输出的函数。它们的一般形式为:
(arg1, arg2, arg3, ...) => <使用参数的表达式>Lambda 用于多个高级运算符,如 reduce 和 map,以实现数据的复杂转换。以下是一些示例:
(x) => x.field (返回 x 的 field 属性,常用于 map)
(x, y) => x + y (求 x 和 y 的和)
(x) => 2 * x (将 x 乘以 2)
(value) => length(value) = 4 (如果 value 的长度为 4,则返回 true)```dataview
CALENDAR file.day
FLATTEN all(map(file.tasks, (x) => x.completed)) AS "allCompleted"
WHERE !allCompleted
```特定类型的交互与值
大多数 dataview 类型与运算符有特殊的交互,或者有额外的字段可以使用索引运算符进行检索。日期(【元数据 > 数据类型 > 可用字段类型 > 日期】)、持续时间(【元数据 > 数据类型 > 可用字段类型 > 持续时间】)以及链接都是如此。有关日期和持续时间的更多信息,请参阅元数据类型中的相应部分(【元数据 > 数据类型】)。
链接
您可以通过链接“索引”来获取对应页面上的值。例如,[[Assignment Math]].duedate 将从页面 Assignment Math 获取值 duedate。
如果您的链接是您在行内字段或 front-matter 中定义的字段,比如 Class:: [[Math]],并且您想获取字段 timetable,那么您可以通过写作 Class.timetable 来索引它。使用 [[Class]].timetable 将查找名为 Class 的页面,而不是 Math!
字面量(Literals)
Dataview 查询语言字面量是表示常量值的表达式,如文本("Science")或数字(2021)。它们可以作为函数(【查询语言参考 > 函数】)或表达式(【查询语言参考 > 表达式】)(如比较)的一部分使用。以下是一些使用字面量的查询(【查询语言参考】)示例:
字面量(数字)2022 用于比较
```dataview
LIST
WHERE file.day.year = 2022
```
字面量(文本)"Math" 用于函数调用
```dataview
LIST
WHERE contains(file.name, "Math")
```
字面量(链接)[[Study MOC]] 用作来源
```dataview
LIST
FROM [[Study MOC]]
```
字面量(日期)date(yesterday) 用于比较
```dataview
TASK
WHERE !completed AND file.day = date(yesterday)
```
字面量(持续时间)dur(2 days) 用于比较
```dataview
LIST
WHERE end - start > dur(2 days)
```字面量是可以作为 Dataview 查询语言(DQL)一部分使用的静态值,即用于比较。
以下是 DQL 中可能的字面量的广泛但不详尽的列表。
常规
| 字面量 | 描述 |
|---|---|
0 |
数字零 |
1337 |
正数 1337 |
-200 |
负数 -200 |
"The quick brown fox jumps over the lazy dog" |
文本(有时称为“字符串”) |
[[Science]] |
指向名为 "Science" 的文件的链接 |
[[]] |
当前文件的链接 |
[1, 2, 3] |
数字 1、2 和 3 的列表 |
[[1, 2],[3, 4]] |
列表的列表 [1, 2] 和 [3, 4] |
{ a: 1, b: 2 } |
一个对象,键为 a 和 b,a 的值为 1,b 的值为 2。 |
date(2021-07-14) |
一个日期(请参阅下面的更多信息) |
dur(2 days 4 hours) |
一个持续时间(请参阅下面的更多信息) |
字面量仅在查询中使用时以这种方式解释,而在作为元数据值使用时则不是。有关字段的可能值及其数据类型,请参阅元数据类型(【元数据 > 数据类型】)。
日期
每当您使用 ISO 格式的日期字段值(【元数据 > 数据类型 > 可用字段类型 > 日期】)时,都需要将这些字段与日期对象进行比较。Dataview 提供了一些常用情况的简写,例如明天、当前周的开始等。请注意,date() 也是一个函数(【date(any)" class="internal-link" target="">查询语言参考 > 函数 > 构造函数 > date(any)】),可以在文本上调用以提取日期。
| 字面量 | 描述 |
|---|---|
date(2021-11-11) |
日期,2021 年 11 月 11 日 |
date(2021-09-20T20:17) |
日期,2021 年 9 月 20 日 20:17 |
date(today) |
表示当前的日期 |
date(now) |
表示当前和时间的日期 |
date(tomorrow) |
表示明天日期的日期 |
date(yesterday) |
表示昨天日期的日期 |
date(sow) |
表示当前周开始的日期 |
date(eow) |
表示当前周结束的日期 |
date(som) |
表示当前月开始的日期 |
date(eom) |
表示当前月结束的日期 |
date(soy) |
表示当前年开始的日期 |
date(eoy) |
表示当前年结束的日期 |
持续时间
持续时间是时间跨度的表示。您可以直接定义它们(【元数据 > 数据类型 > 可用字段类型 > 持续时间】),也可以通过与日期计算而创建它们(【元数据 > 数据类型 > 可用字段类型 > 持续时间】),并将其用于比较等。
秒
| 字面量 | 描述 |
|---|---|
dur(1 s) |
一秒 |
dur(3 s) |
三秒 |
dur(1 sec) |
一秒 |
dur(3 secs) |
三秒 |
dur(1 second) |
一秒 |
dur(3 seconds) |
三秒 |
分钟
| 字面量 | 描述 |
|---|---|
dur(1 m) |
一分钟 |
dur(3 m) |
三分钟 |
dur(1 min) |
一分钟 |
dur(3 mins) |
三分钟 |
dur(1 minute) |
一分钟 |
dur(3 minutes) |
三分钟 |
小时
| 字面量 | 描述 |
|---|---|
dur(1 h) |
一小时 |
dur(3 h) |
三小时 |
dur(1 hr) |
一小时 |
dur(3 hrs) |
三小时 |
dur(1 hour) |
一小时 |
dur(3 hours) |
三小时 |
天
| 字面量 | 描述 |
|---|---|
dur(1 d) |
一天 |
dur(3 d) |
三天 |
dur(1 day) |
一天 |
dur(3 days) |
三天 |
周
| 字面量 | 描述 |
|---|---|
dur(1 w) |
一周 |
dur(3 w) |
三周 |
dur(1 wk) |
一周 |
dur(3 wks) |
三周 |
dur(1 week) |
一周 |
dur(3 weeks) |
三周 |
月
| 字面量 | 描述 |
|---|---|
dur(1 mo) |
一个月 |
dur(3 mo) |
三个月 |
dur(1 month) |
一个月 |
dur(3 months) |
三个月 |
年
| 字面量 | 描述 |
|---|---|
dur(1 yr) |
一年 |
dur(3 yrs) |
三年 |
dur(1 year) |
一年 |
dur(3 years) |
三年 |
组合
| 字面量 | 描述 |
|---|---|
dur(1 s, 2 m, 3 h) |
三小时、两分钟和一秒 |
dur(1 s 2 m 3 h) |
三小时、两分钟和一秒 |
dur(1s 2m 3h) |
三小时、两分钟和一秒 |
dur(1second 2min 3h) |
三小时、两分钟和一秒 |
函数(Functions)
Dataview 函数提供了更高级的数据操作方式。您可以在数据命令(【查询语言参考 > 数据命令】)中使用函数(除了 FROM)来过滤或分组,或者将它们用作额外信息(【查询语言参考 > 查询类型】),如 TABLE 列或 LIST 查询的额外输出,以新的视角查看数据。
函数如何工作
函数是另一种表达式,可以在任何可以使用表达式(【查询语言参考 > 表达式】)的地方使用。函数总是返回一个新值,并遵循以下格式:
functionName(parameter1, parameter2)参数也是表达式(【查询语言参考 > 表达式】),您可以使用字面量、元数据字段,甚至另一个函数作为参数。您可以在此页面的文档中找到参数所需的数据类型(【元数据 > 数据类型】)。请注意函数括号内的信息。方括号中的参数,例如 link(path, [display]) 表示它们是可选的,可以省略。有关每个函数的默认行为,请参阅其说明。
在值列表上调用函数
大多数函数可以应用于单个值(如 number、string、date 等)或这些值的列表。如果函数应用于列表,它也会在函数应用于列表中的每个元素后返回一个列表。例如:
lower("YES") = "yes"
lower(["YES", "NO"]) = ["yes", "no"]
replace("yes", "e", "a") = "yas"
replace(["yes", "ree"], "e", "a") = ["yas", "raa"]这种所谓的“函数向量化”在以下定义中不会明确提及,但在大部分功能中是默认可用的。
构造函数
创建值的构造函数。
object(key1, value1, ...)
创建一个具有给定键和值的新对象。键和值在调用中应交替,并且键应始终是字符串/文本。
object() => 空对象
object("a", 6) => 将 "a" 映射到 6 的对象
object("a", 4, "c", "yes") => 将 a 映射到 4,将 c 映射到 "yes" 的对象list(value1, value2, ...)
创建一个包含给定值的新列表。array 可以作为 list 的别名。
list() => 空列表
list(1, 2, 3) => 包含 1、2 和 3 的列表
array("a", "b", "c") => 包含 "a"、"b" 和 "c" 的列表date(any)
从提供的字符串、日期或链接对象解析日期,如果无法解析则返回 null。
date("2020-04-18") = <表示 2020 年 4 月 18 日的日期对象>
date([[2021-04-16]]) = <针对给定页面的日期对象,指向 file.day>date(text, format)
根据指定格式将文本解析为 luxon DateTime。请注意本地化格式可能无法正常工作。参考 Luxon tokens。
date("12/31/2022", "MM/dd/yyyy") => 2022 年 12 月 31 日的日期时间
date("210313", "yyMMdd") => 2021 年 3 月 13 日的日期时间
date("946778645000", "x") => "2000-01-02T03:04:05" 的日期时间dur(any)
从提供的字符串或持续时间解析持续时间,失败时返回 null。
dur(8 minutes) = <8 分钟>
dur("8 minutes, 4 seconds") = <8 分钟 4 秒>
dur(dur(8 minutes)) = dur(8 minutes) = <8 分钟>number(string)
从给定字符串中提取第一个数字(第一个数值,不是第一位数字,注意),如果可能则返回。若字符串中没有数字,则返回 null。
number("18 years") = 18
number(34) = 34
number("hmm") = nullstring(any)
将任何值转换为“合理”的字符串表示。这有时会产生比直接在查询中使用值更不美观的结果——对于将日期、持续时间、数字等强制转换为字符串以进行操作非常有用。(日期和持续时间会用英文)
string(18) = "18"
string(dur(8 hours)) = "8 hours"
string(date(2021-08-15)) = "August 15th, 2021"link(path, [display])
根据给定的文件路径或名称构建链接对象。如果提供两个参数,则第二个参数是链接的显示名称。
link("Hello") => 指向名为 'Hello' 的页面的链接([[Hello]])
link("Hello", "Goodbye") => 指向名为 'Hello' 的页面,显示为 'Goodbye'([[Hello|Goodbye]])embed(link, [embed?])
将链接对象转换为嵌入链接;尽管在 Dataview 视图中嵌入链接的支持有些不稳定,但图像的嵌入应该可以正常工作。
embed(link("Hello.png")) => 嵌入指向 "Hello.png" 图像的链接,实际呈现为一张图像。(![[Hello.png]])elink(url, [display])
构建指向外部 URL 的链接(如 www.google.com)。如果提供两个参数,则第二个参数是链接的显示名称。
elink("www.google.com") => 指向 google.com 的链接元素([[https://www.google.com]])
elink("www.google.com", "Google") => 指向 google.com 的链接元素,显示为 "Google"([[https://www.google.com|Google]])typeof(any)
获取任何对象的类型以进行检查。可以与其他运算符结合使用,以根据类型更改行为。(下面不是没有翻译,是返回的值就是英文)
typeof(8) => "number"
typeof("text") => "string"
typeof([1, 2, 3]) => "array"
typeof({ a: 1, b: 2 }) => "object"
typeof(date(2020-01-01)) => "date"
typeof(dur(8 minutes)) => "duration"数值操作
round(number, [digits])
将数字四舍五入到给定的位数。如果未指定第二个参数,则四舍五入到最接近的整数;否则,四舍五入到给定的位数。
round(16.555555) = 17
round(16.555555, 2) = 16.56trunc(number)
截断(“切掉”)数字的小数部分。
trunc(12.937) = 12
trunc(-93.33333) = -93
trunc(-0.837764) = 0floor(number)
始终向下取整,返回小于或等于给定数字的最大整数。这意味着负数会变得更加负(原文如此,好表达!)。
floor(12.937) = 12
floor(-93.33333) = -94
floor(-0.837764) = -1ceil(number)
始终向上取整,返回大于或等于给定数字的最小整数。这意味着负数会变得不那么负(可能变为 0,就不是负数了)。
ceil(12.937) = 13
ceil(-93.33333) = -93
ceil(-0.837764) = 0min(a, b, ..)
计算一组参数或数组的最小值。
min(1, 2, 3) = 1
min([1, 2, 3]) = 1
min("a", "ab", "abc") = "a"max(a, b, ...)
计算一组参数或数组的最大值。
max(1, 2, 3) = 3
max([1, 2, 3]) = 3
max("a", "ab", "abc") = "abc"sum(array)
对数组中的所有数值求和。如果在参数中有 null 值,可以通过 nonnull 函数将其消除。
sum([1, 2, 3]) = 6
sum([]) = null
sum(nonnull([null, 1, 8])) = 9product(array)
计算一组数字的乘积。如果在参数中有 null 值,可以通过 nonnull 函数将其消除。
product([1,2,3]) = 6
product([]) = null
product(nonnull([null, 1, 2, 4])) = 8reduce(array, operand)
将列表减少为单个值的通用函数,有效操作符为 "+"、"-"、"*"、"/" 以及布尔操作符 "&" 和 "|"。请注意,使用 "+" 和 "*" 等同于 sum() 和 product() 函数,使用 "&" 和 "|" 匹配 all() 和 any()。
reduce([100, 20, 3], "-") = 77
reduce([200, 10, 2], "/") = 10
reduce(values, "") = 将 values 中的每个元素相乘,等同于 product(values)
reduce(values, this.operand) = 将本地字段 operand 应用到每个值
reduce(["⭐", 3], "") = "⭐⭐⭐",等同于 "⭐" * 3
reduce([1], "+") = 1,有将列表减少为单个元素的效果average(array)
计算数值的平均值。如果参数中有 null 值,可以通过 nonnull 函数将其消除。
average([1, 2, 3]) = 2
average([]) = null
average(nonnull([null, 1, 2])) = 1.5(注意,虽然三个参数,但是 null 被直接移除,所以当做两个参数运算)minby(array, function)
使用提供的函数计算数组的最小值。
minby([1, 2, 3], (k) => k) = 1
minby([1, 2, 3], (k) => 0 - k) => 3
minby(this.file.tasks, (k) => k.due) => (截止日期最早的那条任务)maxby(array, function)
使用提供的函数计算数组的最大值。
maxby([1, 2, 3], (k) => k) = 3
maxby([1, 2, 3], (k) => 0 - k) => 1
maxby(this.file.tasks, (k) => k.due) => (截止日期最晚的那条任务)对象、数组和字符串操作
操作容器对象内部的值。
contains() 等
快速总结,以下是一些示例:
contains("Hello", "Lo") = false
contains("Hello", "lo") = true
icontains("Hello", "Lo") = true
icontains("Hello", "lo") = true
econtains("Hello", "Lo") = false
econtains("Hello", "lo") = true
econtains(["this","is","example"], "ex") = false
econtains(["this","is","example"], "is") = truecontains(object|list|string, value)
检查给定容器类型是否包含给定值。取决于第一个参数是对象、列表还是字符串,此函数的行为会略有不同。此函数区分大小写。
- 对于对象,检查对象是否具有给定名称的键。例如:
contains(file, "ctime") = true contains(file, "day") = true (如果文件在其标题中有日期,否则为 false) - 对于列表,检查数组元素中是否有任何元素等于给定值。例如:
contains(list(1, 2, 3), 3) = true contains(list(), 1) = false - 对于字符串,检查给定值是否是字符串的子字符串。
contains("hello", "lo") = true contains("yes", "no") = false
icontains(object|list|string, value)
不区分大小写的 contains() 版本。
econtains(object|list|string, value)
“精确包含”检查字符串/列表中是否找到精确匹配。此函数区分大小写。
对于字符串,其行为与
contains()(【contains() 等 >contains(object|list|string, value)" class="internal-link" target="">查询语言参考 > 函数 > 对象、数组和字符串操作 >contains()等 >contains(object|list|string, value)】)相同。econtains("Hello", "Lo") = false econtains("Hello", "lo") = true对于列表,检查列表中是否存在精确单词。
econtains(["These", "are", "words"], "word") = false econtains(["These", "are", "words"], "words") = true对于对象,检查对象中是否存在精确键名。它不执行递归检查。
econtains({key:"value", pairs:"here"}, "here") = false econtains({key:"value", pairs:"here"}, "key") = true econtains({key:"value", recur:{recurkey: "val"}}, "value") = false econtains({key:"value", recur:{recurkey: "val"}}, "Recur") = false econtains({key:"value", recur:{recurkey: "val"}}, "recurkey") = false
containsword(list|string, value)
检查 value 在 string 或 list 中是否有精确单词匹配。这是区分大小写的。不同类型输入的输出不同,见示例。
对于字符串,检查单词是否存在于给定字符串中。
containsword("word", "word") = true containsword("word", "Word") = true containsword("words", "Word") = false containsword("Hello there!", "hello") = true containsword("Hello there!", "HeLLo") = true containsword("Hello there chaps!", "chap") = false containsword("Hello there chaps!", "chaps") = true对于列表,返回一个布尔值列表,指示是否找到单词的精确不区分大小写的匹配。
containsword(["I have no words.", "words"], "Word") = [false, false] containsword(["word", "Words"], "Word") = [true, false] containsword(["Word", "Words in word"], "WORD") = [true, true]
extract(object, key1, key2, ...)
从对象中提取多个字段,创建一个仅包含这些字段的新对象。
extract(file, "ctime", "mtime") = object("ctime", file.ctime, "mtime", file.mtime)
extract(object("test", 1)) = object()sort(list)
对列表进行排序,返回一个新排序的列表。
sort(list(3, 2, 1)) = list(1, 2, 3)
sort(list("a", "b", "aa")) = list("a", "aa", "b")reverse(list)
反转列表(逆序,倒序),返回一个新反转的列表。
reverse(list(1, 2, 3)) = list(3, 2, 1)
reverse(list("a", "b", "c")) = list("c", "b", "a")length(object|array)
返回对象中的字段数或数组中的条目数。
length([]) = 0
length([1, 2, 3]) = 3
length(object("hello", 1, "goodbye", 2)) = 2nonnull(array)
返回一个新数组,删除所有 null 值。
nonnull([]) = []
nonnull([null, false]) = [false]
nonnull([1, 2, 3]) = [1, 2, 3]all(array)
仅当数组中的所有值都为真时返回 true。您还可以将多个参数传递给此函数,在这种情况下,仅当所有参数都为真时返回 true。
all([1, 2, 3]) = true
all([true, false]) = false
all(true, false) = false
all(true, true, true) = true您可以将函数作为第二个参数传递,仅当数组中的所有元素与断言匹配时(就是后面函数返回值为真)返回 true。
all([1, 2, 3], (x) => x > 0) = true
all([1, 2, 3], (x) => x > 1) = false
all(["apple", "pie", 3], (x) => typeof(x) = "string") = falseany(array)
如果数组中的任何值为真,则返回 true。您还可以将多个参数传递给此函数,在这种情况下,如果任何参数为真,则返回 true。
any(list(1, 2, 3)) = true
any(list(true, false)) = true
any(list(false, false, false)) = false
any(true, false) = true
any(false, false) = false您可以将函数作为第二个参数传递,仅当数组中的任何元素与断言匹配时返回 true。
any(list(1, 2, 3), (x) => x > 2) = true
any(list(1, 2, 3), (x) => x = 0) = falsenone(array)
如果数组中的所有值都不为真,则返回 true。
none([]) = true
none([false, false]) = true
none([false, true]) = false
none([1, 2, 3]) = false您可以将函数作为第二个参数传递,仅当数组中的所有元素与断言不匹配时返回 true。
none([1, 2, 3], (x) => x = 0) = true
none([true, true], (x) => x = false) = true
none(["Apple", "Pi", "Banana"], (x) => startswith(x, "A")) = falsejoin(array, [delimiter])
将数组中的元素连接成一个字符串(即将它们全部呈现在同一行上)。如果提供第二个参数,则每个元素将由给定分隔符分隔。
join(list(1, 2, 3)) = "1, 2, 3"
join(list(1, 2, 3), " ") = "1 2 3"
join(6) = "6"
join(list()) = ""filter(array, predicate)
根据断言过滤数组中的元素,返回一个新列表,其中包含匹配的元素。
filter([1, 2, 3], (x) => x >= 2) = [2, 3]
filter(["yes", "no", "yas"], (x) => startswith(x, "y")) = ["yes", "yas"]map(array, func)
将函数应用于数组中的每个元素,返回映射结果的列表。
map([1, 2, 3], (x) => x + 2) = [3, 4, 5]
map(["yes", "no"], (x) => x + "?") = ["yes?", "no?"]flat(array, [depth])
将数组的子级连接到所需的深度。默认深度为 1,但可以连接多个级别。例如,可以在执行 GROUP BY 后用于减少 rows 列表的数组深度。
flat(list(1, 2, 3, list(4, 5), 6)) => list(1, 2, 3, 4, 5, 6)
flat(list(1, list(21, 22), list(list(311, 312, 313))), 4) => list(1, 21, 22, 311, 312, 313)
flat(rows.file.outlinks) => 文件的所有外链放在输出的第一层slice(array, [start, [end]])
返回数组的一部分的浅拷贝,选自 start 到 end(不包括 end),其中 start 和 end 表示该数组中项目的索引。
slice([1, 2, 3, 4, 5], 3) = [4, 5] => 从给定位置开始的所有项目,0 为第一个
slice(["ant", "bison", "camel", "duck", "elephant"], 0, 2) = ["ant", "bison"] => 前两个项目
slice([1, 2, 3, 4, 5], -2) = [4, 5] => 从末尾开始计算,最后两个项目
slice(someArray) => someArray 的拷贝字符串操作
regextest(pattern, string)
检查给定的正则表达式是否可以在字符串中找到(使用 JavaScript 正则表达式引擎)。
regextest("\w+", "hello") = true
regextest(".", "a") = true
regextest("yes|no", "maybe") = false
regextest("what", "what's up dog?") = trueregexmatch(pattern, string)
检查给定的正则表达式是否与整个字符串匹配,使用 JavaScript 正则表达式引擎。这与 regextest 不同,后者可以仅匹配文本的部分。
regexmatch("\w+", "hello") = true
regexmatch(".", "a") = true
regexmatch("yes|no", "maybe") = false
regexmatch("what", "what's up dog?") = falseregexreplace(string, pattern, replacement)
替换字符串中所有与正则表达式匹配的实例,用替换字符串替代。这使用 JavaScript 的替换方法,因此您可以使用特殊字符(如 $1)引用第一个捕获组,等等。
regexreplace("yes", "[ys]", "a") = "aea"
regexreplace("Suite 1000", "\d+", "-") = "Suite -"replace(string, pattern, replacement)
将字符串中所有匹配内容替换为替换为给定字符串。
replace("what", "wh", "h") = "hat"
replace("The big dog chased the big cat.", "big", "small") = "The small dog chased the small cat."
replace("test", "test", "no") = "no"lower(string)
将字符串转换为全小写。
lower("Test") = "test"
lower("TEST") = "test"upper(string)
将字符串转换为全大写。
upper("Test") = "TEST"
upper("test") = "TEST"split(string, delimiter, [limit])
根据给定的分隔符字符串拆分字符串。如果提供第三个参数,则限制发生的拆分次数。分隔符字符串被解释为正则表达式。如果分隔符中有捕获组,则匹配会被切割到结果数组中,而不匹配的捕获则为空字符串。
split("hello world", " ") = list("hello", "world")
split("hello world", "\s") = list("hello", "world")
split("hello there world", " ", 2) = list("hello", "there")
split("hello there world", "(t?here)") = list("hello ", "there", " world")
split("hello there world", "( )(x)?") = list("hello", " ", "", "there", " ", "", "world")startswith(string, prefix)
检查字符串是否以给定前缀开头。
startswith("yes", "ye") = true
startswith("path/to/something", "path/") = true
startswith("yes", "no") = falseendswith(string, suffix)
检查字符串是否以给定后缀结尾。
endswith("yes", "es") = true
endswith("path/to/something", "something") = true
endswith("yes", "ye") = falsepadleft(string, length, [padding])
通过在左侧添加填充字符,将字符串填充到所需长度。如果省略填充字符,则默认使用空格。
padleft("hello", 7) = " hello"
padleft("yes", 5, "!") = "!!yes"padright(string, length, [padding])
与 padleft 等效,但向右填充。
padright("hello", 7) = "hello "
padright("yes", 5, "!") = "yes!!"substring(string, start, [end])
获取字符串的切片,从 start 开始,到 end 结束(如果未指定,则到字符串的末尾)。
substring("hello", 0, 2) = "he"
substring("hello", 2, 4) = "ll"
substring("hello", 2) = "llo"
substring("hello", 0) = "hello"truncate(string, length, [suffix])
将字符串截断为最多给定长度,包括后缀(默认为 ...)。通常用于在表中截断长文本。
truncate("Hello there!", 8) = "Hello..."
truncate("Hello there!", 8, "/") = "Hello t/"
truncate("Hello there!", 10) = "Hello t..."
truncate("Hello there!", 10, "!") = "Hello the!"
truncate("Hello there!", 20) = "Hello there!"工具函数
default(field, value)
如果 field 为 null,则返回 value;否则返回 field。用于用默认值替换 null 值。例如,要显示尚未完成的项目,可以使用 "incomplete" 作为默认值:
default(dateCompleted, "incomplete")默认在两个参数中都是向量化的;如果您需要在列表参数上显式使用默认值,请使用 ldefault,它与默认值相同,但不是向量化的。
default(list(1, 2, null), 3) = list(1, 2, 3)
ldefault(list(1, 2, null), 3) = list(1, 2, null)choice(bool, left, right)
一个原始的 if 语句——如果第一个参数为真,则返回左侧;否则返回右侧。
choice(true, "yes", "no") = "yes"
choice(false, "yes", "no") = "no"
choice(x > 4, y, z) = y if x > 4, else zhash(seed, [text], [variant])
根据 seed 以及可选的额外 text 或变体 number 生成哈希。该函数基于这些参数的组合生成一个固定数字,可用于随机化文件或列表/任务的排序顺序。如果您选择基于日期的 seed,例如 "2024-03-17",或其他时间戳,例如 "2024-03-17 19:13",则可以使“随机性”与该时间戳相关联。variant 是一个数字,在某些情况下需要使 text 和 variant 的组合变得唯一。
hash(dateformat(date(today), "YYYY-MM-DD"), file.name) = ...对于给定日期的唯一值
hash(dateformat(date(today), "YYYY-MM-DD"), file.name, position.start.line) = ...在 TASK 查询中的唯一“随机”值此函数可用于 SORT 语句中以随机化顺序。如果您使用 TASK 查询,由于文件名可能相同,您可以添加一些数字,如起始行号(如上所示)以使其成为唯一组合。如果使用类似 FLATTEN file.lists as item 的内容,类似的添加将是 item.position.start.line 作为最后一个参数。
striptime(date)
去除日期的时间组件,仅保留年、月和日。如果您不关心时间,这对于日期比较非常有用。
striptime(file.ctime) = file.cday
striptime(file.mtime) = file.mdaydateformat(date|datetime, string)
使用格式化字符串格式化 Dataview 日期。参考 Luxon tokens。
dateformat(file.ctime,"yyyy-MM-dd") = "2022-01-05"
dateformat(file.ctime,"HH:mm:ss") = "12:18:04"
dateformat(date(now),"x") = "1407287224054"
dateformat(file.mtime,"ffff") = "Wednesday, August 6, 2014, 1:07 PM Eastern Daylight Time"注意: dateformat() 返回一个字符串,而不是日期,因此您无法将其与 date() 的结果或像 file.day 这样的变量进行比较。要进行这些比较,您可以格式化两个参数。
durationformat(duration, string)
使用格式化字符串格式化 Dataview 持续时间。单引号内的任何内容都不会被视为标记,而是按原样显示在输出中。见示例。
您可以使用以下标记:
S表示毫秒s表示秒m表示分钟h表示小时d表示天w表示周M表示月y表示年
durationformat(dur("3 days 7 hours 43 seconds"), "ddd'd' hh'h' ss's'") = "003d 07h 43s"
durationformat(dur("365 days 5 hours 49 minutes"), "yyyy ddd hh mm ss") = "0001 000 05 49 00"
durationformat(dur("2000 years"), "M months") = "24000 months"
durationformat(dur("14d"), "s 'seconds'") = "1209600 seconds"currencyformat(number, [currency])
根据 ISO 4217 中的货币代码,根据您当前的区域设置显示数字。
number = 123456.789
currencyformat(number, "EUR") = €123,456.79 in locale: en_US
currencyformat(number, "EUR") = 123.456,79 € in locale: de_DE
currencyformat(number, "EUR") = € 123 456,79 in locale: nblocaltime(date)
将固定时区中的日期转换为当前时区中的日期。
meta(link)
获取包含链接元数据的对象。当您访问链接上的属性时,返回的是链接文件的属性值。meta 函数使得访问链接本身的属性成为可能。
返回的对象上有几个属性:
meta(link).display
获取链接的显示文本,如果链接没有定义的显示文本,则返回 null。
meta([[2021-11-01|Displayed link text]]).display = "Displayed link text"
meta([[2021-11-01]]).display = nullmeta(link).embed
根据链接是否为嵌入链接返回 true 或 false。嵌入链接以感叹号开头,例如 ![[Some Link]]。
meta(link).path
获取链接的路径部分。
meta([[My Project]]).path = "My Project"
meta([[My Project#Next Actions]]).path = "My Project"
meta([[My Project#^9bcbe8]]).path = "My Project"meta(link).subpath
获取链接的子路径。对于指向文件内标题的链接,子路径将是标题的文本。对于指向块的链接,子路径将是块 ID。如果都不适用,则子路径将为 null。
meta([[My Project#Next Actions]]).subpath = "Next Actions"
meta([[My Project#^9bcbe8]]).subpath = "9bcbe8"
meta([[My Project]]).subpath = null这可以用于选择特定标题下的任务。
```dataview
task
where meta(section).subpath = "Next Actions"
```meta(link).type
根据链接是指向整个文件、文件内的标题,还是文件内的块,具有值 "file"、"header" 或 "block"。
meta([[My Project]]).type = "file"
meta([[My Project#Next Actions]]).type = "header"
meta([[My Project#^9bcbe8]]).type = "block"JavaScript 查询参考(JavaScript Reference)
概览(Overview)
Dataview JavaScript API 允许执行任意 JavaScript 代码,并可以访问 dataview 索引和查询引擎,这对于复杂视图或与其他插件的相互操作非常有用。API 有两种风格:面向插件的和面向用户的(或称为“内联 API 使用”)。
内联访问
你可以通过以下方式创建一个“DataviewJS”块:
dv.pages("#thing")...在此类代码块中执行的代码可以访问 dv 变量,该变量提供了整个代码块相关的 dataview API(例如 dv.table(), dv.pages() 等)。更多信息,请查看代码块 API 参考(【JavaScript 查询参考 > 代码块参考】)。
插件访问
你可以通过 app.plugins.plugins.dataview.api 访问 Dataview 插件 API(来自其他插件或控制台);这个 API 与代码块参考类似,但由于缺少隐式文件来执行查询,参数略有不同。更多信息,请查看插件 API 参考(【问答和资源 > 针对 Dataview 的开发】)。(讲得很好,但是这两个 API 参考,在原文中其实被链接到了一个地方,就是代码块参考,但其实插件访问的说明在 问答和资源——针对 Dataview 的开发 中)
数据数组(Data Arrays)
Dataview 中结果列表的通用表示是 DataArray,这是 JavaScript 数组的一个代理版本,具有扩展的功能。数据数组支持索引和迭代(通过 for 和 for ... of 循环),与普通数组相似,但还包括许多数据操作运算符,如 sort、groupBy、distinct、where 等,使得操作表格数据更加方便。
创建
数据数组由大多数可以返回多个结果的 Dataview API 返回,例如 dv.pages()。您还可以使用 dv.array(<array>) 明确地将普通 JavaScript 数组转换为 Dataview 数组。如果您想将数据数组转换回普通数组,请使用 DataArray#array()。(==这个 # 有点怪,我觉得应该用 .,我测试了,用 # 不行,用 . 可以,那就是原文写错了吧?==)
索引和转换
数据数组支持与普通数组相同的常规索引(如 array[0]),但重要的是,它们还支持查询语言风格的“转换”:如果您用字段名称索引数据数组(如 array.field),它会自动将数组中的每个元素映射到 field,如果 field 本身也是一个数组,则会扁平化 field。
例如,dv.pages().file.name 将返回您库中所有文件名的数据数组;dv.pages("#books").genres 将返回您书籍中所有流派的扁平化列表。
原始接口
以下是数据数组实现的完整接口供参考:
/** 将数组元素映射到某个值的函数。 */
export type ArrayFunc<T, O> = (elem: T, index: number, arr: T[]) => O;
/** 比较两种类型的函数。 */
export type ArrayComparator<T> = (a: T, b: T) => number;
/**
* 代理接口,允许操作基于数组的数据。数据数组上的所有函数生成一个新数组
* (即数组是不可变的)。
*/
export interface DataArray<T> {
/** 数组中元素的总数。 */
length: number;
/** 将数据数组过滤为仅匹配给定谓词的元素。 */
where(predicate: ArrayFunc<T, boolean>): DataArray<T>;
/** 'where' 的别名,适合想要数组语义的人。 */
filter(predicate: ArrayFunc<T, boolean>): DataArray<T>;
/** 通过对每个元素应用函数来映射数据数组中的元素。 */
map<U>(f: ArrayFunc<T, U>): DataArray<U>;
/** 通过对每个元素应用函数来映射数据数组中的元素,然后扁平化结果以生成新数组。 */
flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>;
/** 可变地更改数组中的每个值,返回可以进一步链接的相同数组。 */
mutate(f: ArrayFunc<T, any>): DataArray<any>;
/** 将数组中的条目总数限制为给定值。 */
limit(count: number): DataArray<T>;
/**
* 获取数组的切片。如果 `start` 未定义,则假定为 0;
* 如果 `end` 未定义,则假定为数组的末尾。
*/
slice(start?: number, end?: number): DataArray<T>;
/** 将此数据数组中的值与另一个可迭代对象/数据数组/数组连接。 */
concat(other: Iterable<T>): DataArray<T>;
/** 返回给定元素的第一个索引(可选地从指定位置开始搜索) */
indexOf(element: T, fromIndex?: number): number;
/** 返回满足给定谓词的第一个元素。 */
find(pred: ArrayFunc<T, boolean>): T | undefined;
/** 查找满足给定谓词的第一个元素的索引。如果未找到,则返回 -1。 */
findIndex(pred: ArrayFunc<T, boolean>, fromIndex?: number): number;
/** 如果数组包含给定元素,则返回 true,否则返回 false。 */
includes(element: T): boolean;
/**
* 返回通过将数组中的每个元素转换为字符串并与给定分隔符连接得到的字符串
* (默认为 ', ')。
*/
join(sep?: string): string;
/**
* 返回按给定键排序的数组;可以提供可选的比较器,用于比较键,而不是使用默认的 Dataview 比较器。
*/
sort<U>(key: ArrayFunc<T, U>, direction?: "asc" | "desc", comparator?: ArrayComparator<U>): DataArray<T>;
/**
* 返回按给定键分组的数组;结果数组将具有以下形式的对象
* { key: <key value>, rows: DataArray }。
*/
groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U; rows: DataArray<T> }>;
/**
* 返回不同的条目。如果提供了键,则返回具有不同键的行。
*/
distinct<U>(key?: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<T>;
/** 如果谓词对所有值都为真,则返回 true。 */
every(f: ArrayFunc<T, boolean>): boolean;
/** 如果谓词对至少一个值为真,则返回 true。 */
some(f: ArrayFunc<T, boolean>): boolean;
/** 如果谓词对所有值为假,则返回 true。 */
none(f: ArrayFunc<T, boolean>): boolean;
/** 返回数据数组中的第一个元素。如果数组为空,则返回 undefined。 */
first(): T;
/** 返回数据数组中的最后一个元素。如果数组为空,则返回 undefined。 */
last(): T;
/** 将此数据数组中的每个元素映射到给定键,然后扁平化。 */
to(key: string): DataArray<any>;
/**
* 递归展开给定键,基于该键扁平化树结构为平面数组。对于处理
* 具有“子任务”的层次数据非常有用。
*/
expand(key: string): DataArray<any>;
/** 对数组中的每个元素运行一个 lambda。 */
forEach(f: ArrayFunc<T, void>): void;
/** 计算数组中元素的总和。 */
sum(): number;
/** 计算数组中元素的平均值。 */
avg(): number;
/** 计算数组中元素的最小值。 */
min(): number;
/** 计算数组中元素的最大值。 */
max(): number;
/** 将其转换为普通的 JavaScript 数组。 */
array(): T[];
/** 允许直接迭代数组。 */
[Symbol.iterator](): Iterator<T>;
/** 将索引映射到值。 */
[index: number]: any;
/** 字段的自动扁平化。等同于隐式调用 `array.to("field")` */
[field: string]: any;
}代码块参考(Codeblock Reference)
Dataview JavaScript 代码块使用 dataviewjs 语言规范创建:
```dataviewjs
dv.table([], ...)
```API 通过隐式提供 dv(或 dataview)变量,您可以通过它查询信息、渲染 HTML 和配置视图。
异步 API 调用标记为 ⌛。
查询
查询方法允许您查询 Dataview 索引以获取页面元数据;要渲染这些数据,请使用渲染部分(【JavaScript 查询参考 > 代码块参考 > 渲染】)中的方法。
dv.current()
获取当前脚本执行页面的信息(通过 dv.page())。
dv.pages(source)
接受一个字符串参数 source,其形式与查询语言源(【查询语言参考 > 来源】)相同。
返回一个数据数组(【JavaScript 查询参考 > 数据数组】)的页面对象,这些对象是包含所有页面字段的普通对象。
dv.pages() => 您库中的所有页面
dv.pages("#books") => 所有带有标签 'books' 的页面
dv.pages('"folder"') => 来自文件夹 "folder" 的所有页面
dv.pages("#yes or -#no") => 所有带有标签 #yes 的页面,或不带标签 #no 的页面
dv.pages('"folder" or #tag') => 所有带有标签 #tag 的页面,或来自文件夹 "folder" 的页面请注意,文件夹需要在字符串中用双引号括起来(即 dv.pages("folder") 不起作用,但 dv.pages('"folder"') 起作用)——这是为了与查询语言中源的写法完全匹配。
dv.pagePaths(source)
与 dv.pages 相同,但仅返回匹配给定源的页面路径的数据数组(【JavaScript 查询参考 > 数据数组】)。
dv.pagePaths("#books") => 带有标签 'books' 的页面路径dv.page(path)
将简单路径或链接映射到完整的页面对象,其中包含所有页面字段。自动进行链接解析,如果未提供,则会自动确定扩展名。
dv.page("Index") => /Index 的页面对象
dv.page("books/The Raisin.md") => /books/The Raisin.md 的页面对象渲染
dv.el(element, text)
在给定的 HTML 元素中渲染任意文本。
dv.el("b", "这是一些粗体文本");您可以通过 cls 指定要添加到元素的自定义类,通过 attr 指定附加属性:
dv.el("b", "这是一些文本", { cls: "dataview dataview-class", attr: { alt: "不错!" } });dv.header(level, text)
渲染给定文本为 1 - 6 级标题。
dv.header(1, "大标题!");
dv.header(6, "小标题");dv.paragraph(text)
在段落中渲染任意文本。
dv.paragraph("这是一些文本");dv.span(text)
在 span 中渲染任意文本(与段落不同,没有上下填充(padding))。(这个括号补充的有点迷,span 是行内元素,而 p 是块元素,这才是重要区别。但实际效果我建议自行查看渲染出来的代码。)
dv.span("这是一些文本");dv.execute(source)
执行任意 Dataview 查询并将视图嵌入当前页面。
dv.execute("LIST FROM #tag");
dv.execute("TABLE field1, field2 FROM #thing");dv.executeJs(source)
执行任意 DataviewJS 查询并将视图嵌入当前页面。
dv.executeJs("dv.list([1, 2, 3])");dv.view(path, input)
复杂函数,允许自定义视图。将尝试在给定路径加载 JavaScript 文件,传递 dv 和 input 并允许其执行。这使您可以在多个页面之间重用自定义视图代码。请注意,这是一个异步函数,因为它涉及文件 I/O - 确保 await 结果!(==官方说是异步的,但官方没有标记 ⌛。当然,也合理,因为多数场景下并不需要等待它返回的结果,这种情况也不是必须使用 await==)
await dv.view("views/custom", { arg1: ..., arg2: ... });如果您还想在视图中包含自定义 CSS,可以传递包含 view.js 和 view.css 的文件夹路径;CSS 将自动添加到视图中:
views/custom
-> view.js
-> view.css视图脚本可以访问 dv 对象(API 对象)和 input 对象,该对象正是 dv.view() 的第二个参数。
请注意,dv.view() 不能从以点开头的目录读取,如 .views。以下是错误用法的示例:
await dv.view(".views/view1", { arg1: 'a', arg2: 'b' });尝试此操作将产生以下异常:
Dataview: custom view not found for '.views/view1/view.js' or '.views/view1.js'.还要注意,目录路径始终从库根目录开始。(其实在没有冲突的情况下,只写文件夹名称就可以了,Dataview 找得到)
示例(视图)
在此示例中,我们在 scripts 目录中有一个名为 view1.js 的自定义脚本文件。
文件: scripts/view1.js
console.log(`加载 view1`);
function foo(...args) {
console.log('foo 被调用,参数为', ...args);
}
foo(input)我们在 projects 下有一个 Obsidian 文档。我们将使用 scripts/view1.js 路径从该文档调用 dv.view()。
文档: projects/customViews.md
await dv.view("scripts/view1", { arg1: 'a', arg2: 'b' })当上述脚本执行时,将打印以下内容:(什么都没有?!太正常了,内容是打印在控制台的,笔记中啥也没得显示)
加载 view1
foo 被调用,参数为 {arg1: 'a', arg2: 'b'}数据视图
dv.list(elements)
渲染元素的 Dataview 列表;接受普通数组和数据数组。
dv.list([1, 2, 3]) => 列表 1, 2, 3
dv.list(dv.pages().file.name) => 所有文件名的列表
dv.list(dv.pages().file.link) => 所有文件链接的列表
dv.list(dv.pages("#book").where(p => p.rating > 7)) => 所有评分大于 7 的书籍列表dv.taskList(tasks, groupByFile)
渲染 Task 对象的 Dataview 列表,获取方式为 page.file.tasks。默认情况下,此视图将自动按来源文件对任务进行分组。如果您明确提供 false 作为第二个参数,它将作为一个统一的列表渲染。
// 列出所有标记为 '#project' 的页面中的任务
dv.taskList(dv.pages("#project").file.tasks)
// 列出所有 *未完成* 的任务,来自标记为 #project 的页面
dv.taskList(dv.pages("#project").file.tasks
.where(t => !t.completed))
// 列出所有标记为 '#tag' 的任务,来自标记为 #project 的页面
dv.taskList(dv.pages("#project").file.tasks
.where(t => t.text.includes("#tag")))
// 列出所有标记为 '#project' 的页面中的任务,不进行分组。
dv.taskList(dv.pages("#project").file.tasks, false)dv.table(headers, elements)
渲染 Dataview 表格。headers 是列标题的数组。elements 是行的数组。每一行本身就是一个列的数组。在一行中,每个数组类型的列将以项目符号形式渲染。
dv.table(
["Col1", "Col2", "Col3"],
[
["Row1", "Dummy", "Dummy"],
["Row2",
["Bullet1",
"Bullet2",
"Bullet3"],
"Dummy"],
["Row3", "Dummy", "Dummy"]
]
);一个如何渲染按评分排序的书籍信息简单表格的示例。
dv.table(["File", "Genre", "Time Read", "Rating"], dv.pages("#book")
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b["time-read"], b.rating]))Markdown 数据视图
将渲染为纯 Markdown 字符串的函数,您可以根据需要渲染或操作这些字符串。
dv.markdownTable(headers, values)
相当于 dv.table(),渲染具有给定标题列表和 2D 数组的表格,但返回纯 Markdown。
// 渲染按评分排序的书籍信息简单表格。
const table = dv.markdownTable(["File", "Genre", "Time Read", "Rating"], dv.pages("#book")
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b["time-read"], b.rating]))
dv.paragraph(table);dv.markdownList(values)
相当于 dv.list(),渲染给定元素的列表,但返回纯 Markdown。
const markdown = dv.markdownList([1, 2, 3]);
dv.paragraph(markdown);dv.markdownTaskList(tasks)
相当于 dv.taskList(),渲染任务列表,但返回纯 Markdown。
const markdown = dv.markdownTaskList(dv.pages("#project").file.tasks);
dv.paragraph(markdown);工具
dv.array(value)
将给定值或数组转换为 Dataview 数据数组(【JavaScript 查询参考 > 数据数组】)。如果值已经是数据数组,则返回原值。
dv.array([1, 2, 3]) => dataview 数据数组 [1, 2, 3]dv.isArray(value)
如果给定值是数组或 Dataview 数组,则返回 true。
dv.isArray(dv.array([1, 2, 3])) => true
dv.isArray([1, 2, 3]) => true
dv.isArray({ x: 1 }) => falsedv.fileLink(path, [embed?], [display-name])
将文本路径转换为 Dataview Link 对象;您还可以选择指定链接是否嵌入以及其显示名称。
dv.fileLink("2021-08-08") => 链接到名为 "2021-08-08" 的文件
dv.fileLink("book/The Raisin", true) => 嵌入链接到 "The Raisin"
dv.fileLink("Test", false, "Test File") => 链接到文件 "Test",显示名称为 "Test File"dv.sectionLink(path, section, [embed?], [display?])
将文本路径 + 部分名称转换为 Dataview Link 对象;您还可以选择指定链接是否嵌入及其显示名称。
dv.sectionLink("Index", "Books") => [[Index#Books]]
dv.sectionLink("Index", "Books", false, "My Books") => [[Index#Books|My Books]]dv.blockLink(path, blockId, [embed?], [display?])
将文本路径 + 块 ID 转换为 Dataview Link 对象;您可以选择指定链接是否嵌入及其显示名称。
dv.blockLink("Notes", "12gdhjg3") => [[Index#^12gdhjg3]]dv.date(text)
将文本和链接强制转换为 luxon DateTime;如果提供的是 DateTime,则返回原值。
dv.date("2021-08-08") => 2021年8月8日的 DateTime
dv.date(dv.fileLink("2021-08-07")) => 2021年8月7日的 DateTimedv.duration(text)
将文本强制转换为 luxon Duration;使用与 Dataview 持续时间类型相同的解析规则。
dv.duration("8 minutes") => 持续时间 { 8 分钟 }
dv.duration("9 hours, 2 minutes, 3 seconds") => 持续时间 { 9 小时, 2 分钟, 3 秒 }dv.compare(a, b)
根据 Dataview 的默认比较规则比较两个任意 JavaScript 值;如果您正在编写自定义比较器并希望回退到默认行为,则非常有用。如果 a < b,返回负值;如果 a = b,返回 0;如果 a > b,返回正值。
dv.compare(1, 2) = -1
dv.compare("yes", "no") = 1
dv.compare({ what: 0 }, { what: 0 }) = 0dv.equal(a, b)
比较两个任意 JavaScript 值,如果它们根据 Dataview 的默认比较规则相等,则返回 true。
dv.equal(1, 2) = false
dv.equal(1, 1) = truedv.clone(value)
深度克隆任何 Dataview 值,包括日期、数组和链接。
dv.clone(1) = 1
dv.clone({ a: 1 }) = { a: 1 }dv.parse(value)
将任意字符串对象解析为复杂的 Dataview 类型 (主要支持链接、日期和持续时间)。
dv.parse("[[A]]") = 链接 { path: A }
dv.parse("2020-08-14") = DateTime { 2020-08-14 }
dv.parse("9 seconds") = 持续时间 { 9 秒 }文件 I/O
这些实用方法都包含在 dv.io 子 API 中,并且都是 异步的(标记为 ⌛)。(使用相对路径可能不成功,我一般使用相对于根目录的相对路径,但也可能是我书写的相对路径格式不对)
⌛ dv.io.csv(path, [origin-file])
从给定路径(链接或字符串)加载 CSV。相对路径将相对于可选的原始文件解析(如果未提供,则默认为当前文件)。返回一个 Dataview 数组,每个元素包含一个 CSV 值的对象;如果文件不存在,则返回 undefined。
await dv.io.csv("hello.csv") => [{ column1: ..., column2: ...}, ...]⌛ dv.io.load(path, [origin-file])
异步加载给定路径(链接或字符串)的内容。相对路径将相对于可选的原始文件解析(如果未提供,则默认为当前文件)。返回文件的字符串内容,如果文件不存在,则返回 undefined。
await dv.io.load("File") => "# 文件\n这是一个示例文件..."dv.io.normalize(path, [origin-file])
将相对链接或路径转换为绝对路径。如果提供了 origin-file,则解析就像从该文件解析链接;如果没有,则路径相对于当前文件解析。
dv.io.normalize("Test") => "dataview/test/Test.md",如果在 "dataview/test" 内
dv.io.normalize("Test", "dataview/test2/Index.md") => "dataview/test2/Test.md",与当前文件无关查询评估
⌛ dv.query(source, [file, settings])
执行一个 Dataview 查询,并将结果作为结构化返回。此函数的返回类型因执行的查询类型而异,但始终会返回一个带有 type 的对象,表示返回类型。此版本的 query 返回结果类型 —— 您可能想使用 tryQuery,它在查询执行失败时抛出错误。
await dv.query("LIST FROM #tag") =>
{ successful: true, value: { type: "list", values: [value1, value2, ...] } }
await dv.query(`TABLE WITHOUT ID file.name, value FROM "path"`) =>
{ successful: true, value: { type: "table", headers: ["file.name", "value"], values: [["A", 1], ["B", 2]] } }
await dv.query("TASK WHERE due") =>
{ successful: true, value: { type: "task", values: [task1, task2, ...] } }dv.query 接受两个额外的可选参数:
file:解析查询的文件路径(在引用this的情况下)。默认为当前文件。settings:运行查询的执行设置。这主要是一个高级用例(建议您直接检查 API 实现以查看所有可用选项)。
⌛ dv.tryQuery(source, [file, settings])
与 dv.query 完全相同,但在短脚本中更方便,因为:执行失败将作为 JavaScript 异常引发,而不是结果类型。
⌛ dv.queryMarkdown(source, [file], [settings])
相当于 dv.query(),但返回渲染的 Markdown。
await dv.queryMarkdown("LIST FROM #tag") =>
{ successful: true, value: { "- [[Page 1]]\n- [[Page 2]]" } }⌛ dv.tryQueryMarkdown(source, [file], [settings])
与 dv.queryMarkdown() 完全相同,但在解析失败时抛出错误。
dv.tryEvaluate(expression, [context])
评估任意 Dataview 表达式(如 2 + 2 或 link("text") 或 x * 9);在解析或
评估失败时抛出 Error。this 是一个始终可用的隐式变量,指代当前文件。
dv.tryEvaluate("2 + 2") => 4
dv.tryEvaluate("x + 2", {x: 3}) => 5
dv.tryEvaluate("length(this.file.tasks)") => 当前文件中的任务数量dv.evaluate(expression, [context])
评估任意 Dataview 表达式(如 2 + 2 或 link("text") 或 x * 9),返回结果的 Result 对象。您可以通过检查 result.successful 解包结果类型(然后获取 result.value 或 result.error)。如果您想要一个在评估失败时抛出错误的简单 API,请使用 dv.tryEvaluate。
dv.evaluate("2 + 2") => 成功 { value: 4 }
dv.evaluate("2 +") => 失败 { error: "Failed to parse ... " }代码块示例(Codeblock Examples)
分组书籍
按类型分组书籍,然后通过简单使用 Dataview 渲染 API 为每个类型创建一个按评分排序的表格:
for (let group of dv.pages("#book").groupBy(p => p.genre)) {
dv.header(3, group.key);
dv.table(["名称", "阅读时间", "评分"],
group.rows
.sort(k => k.rating, 'desc')
.map(k => [k.file.link, k["time-read"], k.rating]))
}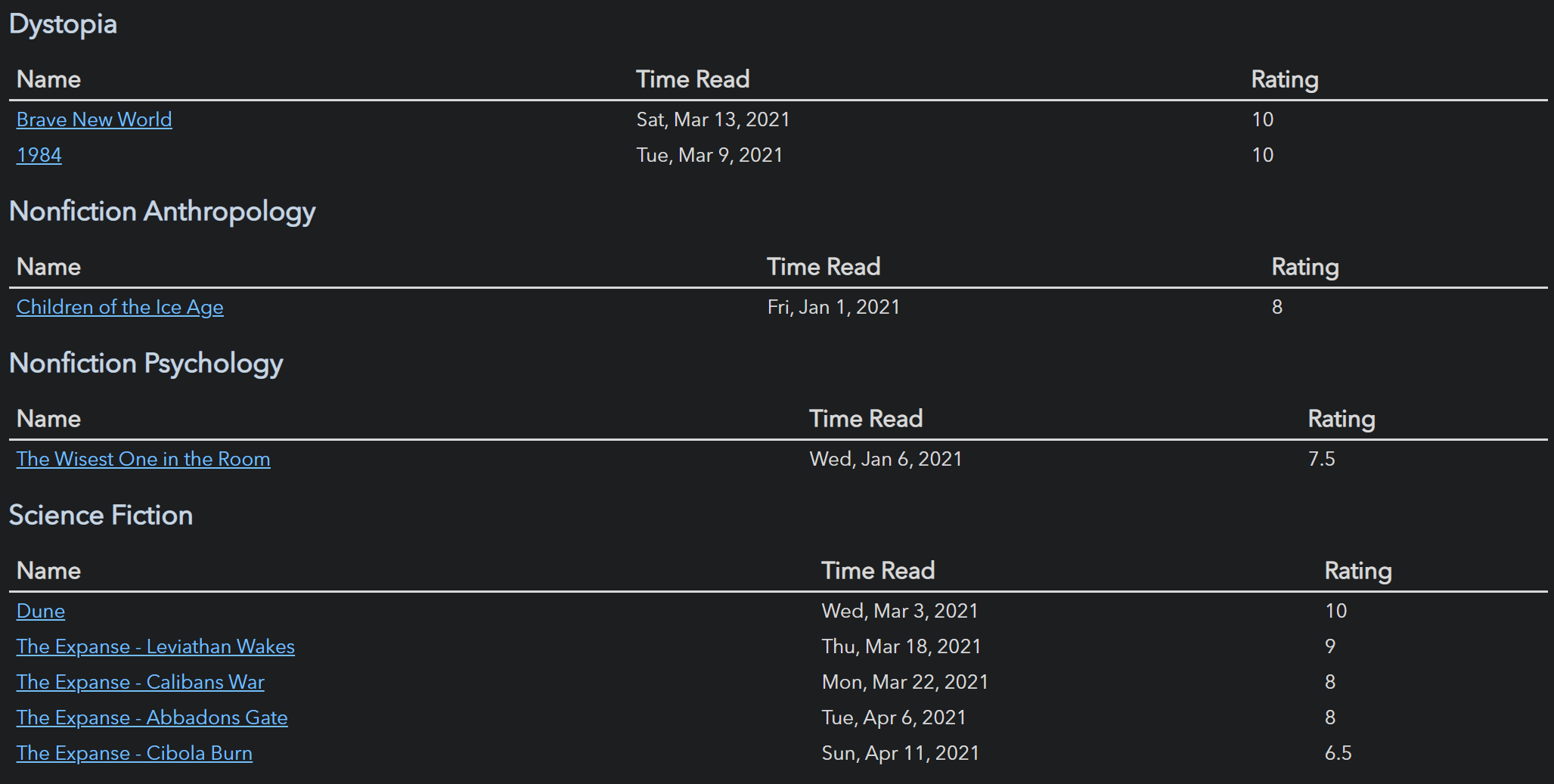
查找所有直接和间接链接的页面
使用简单的集合 + 栈深度优先搜索来查找所有链接到当前笔记或您选择的笔记的笔记:
let page = dv.current().file.path;
let pages = new Set();
let stack = [page];
while (stack.length > 0) {
let elem = stack.pop();
let meta = dv.page(elem);
if (!meta) continue;
for (let inlink of meta.file.inlinks.concat(meta.file.outlinks).array()) {
console.log(inlink);
if (pages.has(inlink.path)) continue;
pages.add(inlink.path);
stack.push(inlink.path);
}
}
// 数据现在是每个直接或间接链接到当前页面的页面的文件元数据。
let data = dv.array(Array.from(pages)).map(p => dv.page(p));问答和资源(FAQ and Resources)
常见问题解答(Frequently Asked Questions)
一系列关于 Dataview 查询和表达式语言的常见问题。
如何使用与关键字同名的字段(如 "from","where")?
Dataview 提供了一个特殊的“虚拟”字段 row,可以通过它获取与 Dataview 关键字冲突的字段:
row.from /* 同 "from" */
row.where /* 同 "where" */如何访问名称中带空格的字段?
有两种方法:
- 使用该字段的规范化 Dataview 名称——只需将名称转换为小写并用短横线("-")替换空格。例如,
Field With Space In It变为field-with-space-in-it。 - 使用隐式的
row字段:row["Field With Space In It"]
你们有没有学习资源的列表?
有的!请查看资源页面(【问答和资源 > 资源与支持】)。
我可以保存查询结果以便重用吗?
您可以使用 dv.view 函数(【dv.view(path, input)" class="internal-link" target="">JavaScript 查询参考 > 代码块参考 > 渲染 > dv.view(path, input)】)编写可重用的 JavaScript 查询。在 DQL 中,除了可以将查询写入模板并使用该模板(可以使用核心插件模板或流行的社区插件Templater),您还可以通过内联 DQL (【查询语言、JS 和行内查询】)在元数据字段中保存计算,例如:
start:: 07h00m
end:: 18h00m
pause:: 01h30m
duration:: `= this.end - this.start - this.pause`您可以列出该值(在我们的示例中为 9h 30m),例如在一个表格中,而无需重复计算:
```dataview
TABLE start, end, duration
WHERE duration
```这将返回:
| Files (1) | start | end | duration |
|---|---|---|---|
| 示例 | 7 小时 | 18 小时 | 9 小时,30 分钟 |
但将内联 DQL 存储在字段中有一个限制:虽然结果中显示的值是计算后的值,但元数据字段中保存的值仍然是您的内联 DQL 算式。该值实际上是 = this.end - this.start - this.pause。这意味着您无法过滤内联的结果,例如:
```dataview
TABLE start, end, duration
WHERE duration > dur("10h")
```这将返回示例页面,即使结果不符合 WHERE 子句,因为您比较的值是 = this.end - this.start - this.pause,而不是一个持续时间。
如何隐藏表格查询的结果计数?
在 Dataview 0.5.52 中,您可以通过设置隐藏表格和任务查询的结果计数。前往 Dataview 的设置 -> 显示结果计数。
如何为我的查询设置样式?
您可以使用 CSS 片段为 Obsidian 定义自定义样式。因此,如果您将 cssclasses: myTable 定义为一个属性,并启用下面的片段,您可以设置 Dataview 表格的背景颜色。类似地,针对 TASK 或 LIST 查询的外部 <ul>,您可以分别使用 ul.contains-task-list 或 ul.list-view-ul。
.myTable dataview.table {
background-color: green
}通常情况下,页面上的特定表格没有唯一的 ID,因此提到的目标适用于任何定义了该 cssclasses 的笔记和所有表格。目前,您无法使用普通查询针对特定表格,但如果您使用 JavaScript,可以通过以下方式直接将 clsname 类添加到查询结果中:
dv.container.className += ' clsname'然而,有一个技巧可以使用标签在 Obsidian 中针对任何表格,如下面的示例所示,这适用于任何包含该标签的表格。这适用于手动和 Dataview 生成的表格。要使下面的片段生效,请在表格输出的 任何地方 添加标签 #myId。
[href="#myId"] {
display: none; /* 隐藏表格视图中的标签 */
}
table:has([href="#myId"]) {
/* 按照您的喜好样式化表格 */
background-color: #262626;
& tr:nth-child(even) td:first-child {
background-color: #3f3f3f;
}
}这将使整个表格背景为灰色,且每个偶数行的第一个单元格为不同的灰色变体。免责声明: 我们不是样式专家,这只是一个示例,展示了样式化表格不同部分所需的一些语法。
此外,在样式化 Dataview 表格列中,@s-blu 描述了一种使用 <span> 样式化表格单元格(和列)不同部分的替代技巧。
示例(Examples)
一小部分 Dataview 查询语言的简单用法。
显示游戏文件夹中的所有游戏,按评分排序,并附带一些元数据:
查询
TABLE
time-played AS "游戏时长",
length AS "长度",
rating AS "评分"
FROM "games"
SORT rating DESC输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| 文件 | 游戏时长 | 长度 | 评分 |
|---|---|---|---|
| Outer Wilds | 2020年11月19日 - 21日 | 15小时 | 9.5 |
| Minecraft | 一直在玩。 | 2000小时 | 9.5 |
| Pillars of Eternity 2 | 2019年8月 - 10月 | 100小时 | 9 |
列出所有 MOBA 或 CRPG 类型的游戏。
查询
LIST FROM #games/mobas OR #games/crpg输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
列出所有未完成项目中的任务:
查询
TASK FROM "dataview"输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- 我是一个任务。
- 我是另一个任务。
- 我可能是一个任务,但谁知道呢。
- 确定这是否是一个任务。
- 我是一个已完成的任务。
列出 books 文件夹中的所有文件,按最后修改时间排序:
查询
TABLE file.mtime AS "最后修改时间"
FROM "books"
SORT file.mtime DESC输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
| 文件 | 最后修改时间 |
|---|---|
| Atomic Habits | 2021年8月7日 11:06 PM |
| Can't Hurt Me | 2021年8月7日 10:58 PM |
| Deep Work | 2021年8月7日 10:52 PM |
列出所有标题中包含日期的文件(格式为 yyyy-mm-dd),并按日期顺序列出。
查询
LIST file.day WHERE file.day
SORT file.day DESC输出(只是演示一下输出格式,别点了,这里的都不是有效链接)
- 2021-08-07: 2021年8月7日
- 2020-08-10: 2020年8月10日
针对 Dataview 的开发(Developing Against Dataview)
Dataview 包含一个面向插件的高级 API,以及 TypeScript 定义和一个工具库;要安装它,只需使用:
npm install -D obsidian-dataview要验证是否安装了正确的版本,可以运行 npm list obsidian-dataview。如果未报告最新版本(当前为 0.5.64),可以执行:
npm install obsidian-dataview@0.5.64注意:如果您的本地系统尚未安装 Git,则需要先安装它。您可能需要重启设备以完成 Git 安装,然后才能安装 Dataview API。
访问 Dataview API
您可以使用 getAPI() 函数获取 Dataview 插件 API;这将返回一个 DataviewApi 对象,提供各种实用工具,包括渲染 dataview、检查 dataview 版本、挂钩 dataview 事件生命周期以及查询 dataview 元数据。
import { getAPI } from "obsidian-dataview";
const api = getAPI();有关可用的完整 API 定义,请查看 index.ts 或插件 API 定义 plugin-api.ts。
绑定 Dataview 事件
您可以绑定到 dataview 元数据事件,这些事件在所有文件更新和更改时触发:
plugin.registerEvent(plugin.app.metadataCache.on("dataview:index-ready", () => {
...
}));
plugin.registerEvent(plugin.app.metadataCache.on("dataview:metadata-change",
(type, file, oldPath?) => { ... }));有关所有钩子在 MetadataCache 上的事件,请查看 index.ts。
值工具
您可以访问各种类型工具,允许您检查对象的类型并通过 Values 进行比较:
import { getAPI, Values } from "obsidian-dataview";
const field = getAPI(plugin.app)?.page('sample.md').field;
if (!field) return;
if (Values.isHtml(field)) // 执行某些操作
else if (Values.isLink(field)) // 执行某些操作
// ...资源与支持(Resources and Support)
开始使用 Dataview 可能会有一些学习曲线。此页面汇集了一些资源,帮助您入门。Dataview 经常会更新新功能和修复,因此请注意这些资源可能略有过时。欢迎直接为此列表、文档做贡献,或联系原始来源的作者以获取更新。
资源
Obsidian Hub
- SkepticMystic 的 Dataview 介绍,并附有 文本指南
YouTube 视频
- SkepticMystic 的上述社区讲座
- Dataview 插件:如何使用这个强大的 Obsidian 插件(附示例) by Filipe Donadio
- 用 Dataview 自动化您的 Vault - 如何在 Obsidian 中使用 Dataview by FromSergio
- 如何使用 Obsidian Dataview 插件 by Nicole van der Hoeven
- Dataview 插件介绍 - Obsidian 社区讲座
示例 Vault
- @s-blu 很好地整理了 一个示例查询的 Vault,您可以将其用作游乐场。
博客文章
GitHub 讨论
GitHub 仓库有一个相对活跃的 讨论页面,有许多已回答的问题。
Obsidian 论坛
Obsidian 论坛提供了大量问题和答案以及其他有趣的内容。尝试在论坛中搜索答案,特别是看起来是初学者的问题。
Discord
Obsidian 成员小组 Discord 服务器有一个 #dataview 频道。再次强调,您的问题很可能之前有人问过,因此请尝试先搜索,尽管众所周知 Discord 的搜索功能可能不太稳定。如果您找不到满意的答案,这是您获得实时支持的最佳途径,但不能保证即时回复。不过,有很多乐于助人的人,所以不要害怕提问。
支持
当您有问题时,该去哪里寻求帮助?我们建议您尝试以下方法:
- 在 GitHub 讨论和 Obsidian 论坛中搜索您的问题。
- 在 Discord 中搜索可能的解决方案。
- 根据问题的复杂性:
- 如果您需要近乎同步的沟通,请使用 Discord。请注意,我们是一个志愿者社区,回复可能会有延迟。
- 如果您预计您的问题需要多天时间并且需要异步沟通,请开启 GitHub 讨论。
- 如果您发现了错误,请在 仓库的问题页面 中报告。
Dataview 之友(Friends of Dataview)
以下是一些可能对 Dataview 相关工作流有帮助的插件:
- MetaEdit - 轻松添加或更新 YAML 属性和 Dataview 字段。
另外,还有一些非详尽的插件,它们利用 Dataview 进行一些功能所需的重型处理:
- Kanban - 在 Obsidian 中创建基于 Markdown 的看板。
- Breadcrumbs - 让您在 Obsidian vault 中可视化自定义构建的层次结构。
- Supercharged Links - 基于笔记元数据样式化 Obsidian vault 中的链接。
完整列表可以通过 GitHub 的 Dependents 功能找到。
更新日志(Changelog)(不做翻译)
可以访问:https://blacksmithgu.github.io/obsidian-dataview/changelog/,因我无法保证实更新这些内容,所以不做翻译。
大老鼠喵喵叫
虽然有 AI 辅助,这依然是一份蛮辛苦的工作,毕竟得了解并理解其中的每个细节,才能发现其中矛盾的地方,并标注出来。而且 AI 还会翻译失真,甚至偷工减料,都得仔细提防着,并反复比对。
虽然说能做点对大家有用的事情,我就觉得挺开心的,但可以预见的,将此内容转发到其他各处,并附以:“家人们,我为你们找到宝藏啦,看在我这么辛苦的份上,点点赞啊”这样会赚到更多的热度,点赞,和小钱钱。(我倒也不介意,毕竟更多人看到了)
但是,有些事情,总得有人去做吧。
如果,对你有帮助,请我喝杯咖啡吧(老鼠爱发电),或者留个言(https://meta.appinn.net/t/topic/59541),让我感受到读者的存在。
翻译完之后还有二次校对,内链添加的工作,以及日后跟着官方文档更新……我不确定我能坚持到哪一步。如果大家都只是默默地读完离开,我就只是在孤身作战了,连读者都感受不到,如同在深夜中坚持独自前行……